Формальные системы и языки программирования
Лекция 13
Формальные системы и языки программирования
Вопросы:
- Описание синтаксиса языка программирования
- Общая структура компилятора
- Лексический анализатор программы
- Синтаксический анализатор программы
- Семантический анализатор программы
- Генерация внутреннего представления программы
- Интерпретатор программы
Литература
Гордеев А.В., Молчанов А.Ю. Системное программное обеспечение. СПб.: Питер, 2001.
Введение
Предлагаемый материал посвящен основам классической теории компиляторов – одной из важнейших составных частей системного программного обеспечения.
Несмотря на более чем полувековую историю вычислительной техники, формально годом рождения теории компиляторов можно считать 1957, когда появился первый компилятор языка Фортран, созданный Бэкусом и дающий достаточно эффективный объектный код. До этого времени создание компиляторов было весьма «творческим» процессом. Лишь появление теории формальных языков и строгих математических моделей позволило перейти от «творчества» к «науке». Именно благодаря этому, стало возможным появление сотен новых языков программирования.
Несмотря на то, что к настоящему времени разработаны тысячи различных языков и их компиляторов, процесс создания новых приложений в этой области не прекращается. Это связно как с развитием технологии производства вычислительных систем, так и с необходимостью решения все более сложных прикладных задач. Такая разработка может быть обусловлена различными причинами, в частности, функциональными ограничениями, отсутствием локализации, низкой эффективностью существующих компиляторов. Поэтому основы теории языков и формальных грамматик, а также практические методы разработки компиляторов лежат в фундаменте инженерного образования по информатике и вычислительной технике.
1. Описание синтаксиса языка программирования
Существуют три основных метода описания синтаксиса языков программирования: формальные грамматики, формы Бэкуса-Наура и диаграммы Вирта.
Формальные грамматики
Определение 1.1. Формальной грамматикой называется четверка вида:
, (1.1)
где VN - конечное множество нетерминальных символов грамматики (обычно прописные латинские буквы);
VT - множество терминальных символов грамматики (обычно строчные латинские буквы, цифры, и т.п.), VT VN =;
Р – множество правил вывода грамматики, являющееся конечным подмножеством множества (VT VN)+ (VT VN)*; элемент (, ) множества Р называется правилом вывода и записывается в виде (читается: «из цепочки выводится цепочка »);
S – начальный символ грамматики, S VN.
Для записи правил вывода с одинаковыми левыми частями вида используется сокращенная форма записи .
Пример 1.1. Опишем с помощью формальных грамматик синтаксис паскалеподобного модельного языка М. Грамматика будет иметь правила вывода вида:
P program D2 B.
D2 var D1
D1 D | D1; D
D I1: int | I1: bool
I1 I | I1, I
B begin S1 end
S1 S | S1; S
S begin S1 end | if E then S else S | while E do S | read(I) | write(E)
E E1 | E1=E1 | E1>E1 | E1<E1
El T | T+E1 | T-E1 | TEl
T F | F*T | F/T | FT
F I | N | L | F | (E)
L true | false
I C | IC | IR
N R | NR
C a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z
R 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Формы Бэкуса-Наура (БНФ)
Метаязык, предложенный Бэкусом и Науром, использует следующие обозначения:
- символ «::=» отделяет левую часть правила от правой (читается: «определяется как»);
- нетерминалы обозначаются произвольной символьной строкой, заключенной в угловые скобки «<» и «>»;
- терминалы - это символы, используемые в описываемом языке;
- правило может определять порождение нескольких альтернативных цепочек, отделяемых друг от друга символом вертикальной черты «|» (читается: «или»).
Пример 1.2. Определение понятия «идентификатор» с использованием БНФ имеет вид:
<идентификатор> ::= <буква> | <идентификатор> <буква>
| <идентификатор> <цифра>
<буква> :: = a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w |
| x | y | z
<цифра> :: = 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Расширенные формы Бэкуса-Наура (РБНФ)
Для повышения удобства и компактности описаний, в РБНФ вводятся следующие дополнительные конструкции (метасимволы):
- квадратные скобки «[» и «]» означают, что заключенная в них синтаксическая конструкция может отсутствовать;
- фигурные скобки «{» и «}» означают повторение заключенной в них синтаксической конструкции ноль или более раз;
- сочетание фигурных скобок и косой черты «{/» и «/}» используется для обозначения повторения один и более раз;
- круглые скобки «(» и «)» используются для ограничения альтернативных конструкций.
Пример 1.3. В соответствии с данными правилами синтаксис модельного языка М будет выглядеть следующим образом:
<буква> ::= a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w |
x | y | z
<цифра> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
<идентификатор> ::= <буква> { <буква> | <цифра> }
<число> ::= {/< цифра> /}
<ключевое_слово> ::= program | var | begin | end | int | bool | read | write | if |
then | else | while | do | true | false
<разделитель> ::= ( | ) | , | ; | : | := | . | { | } |+ | - | * | / | | | | = | < | >
<программа> ::= program <описание> ; <тело>.
<описание> ::= var <идентификатор> {, <идентификатор>}: (int | bool)
<тело> ::= begin {<оператор>; } end
<оператор> ::= <присваивания> | <условный> | <цикла> | <составной> |
<ввода> | <вывода>
<присваивания> ::= <идентификатор> := <выражение>
<условный> ::= if <выражение> then <оператор> else <оператор>
<цикла> ::= while <выражение> do <оператор>
<составной>:: = begin {<оператор> ;} end
<ввода>:: = read(<идентификатор>)
<вывода>:: = write(<выражение>)
<выражение>:: = <сумма> | <сумма> ( = | < | >) <сумма>
<сумма> ::= <произведение> { (+ | - | ) <произведение>}
<произведение>:: = <множитель> { (* | / | ) <множитель>}
<множитель>:: = <идентификатор> | <число> | <логическая_константа> |
<множитель> | (<выражение>)
<логическая_константа>:: = true | false
Диаграммы Вирта
В метаязыке диаграмм Вирта используются графические примитивы, представленные на рисунке 1.1.
При построении диаграмм учитывают следующие правила:
- каждый графический элемент, соответствующий терминалу или нетерминалу, имеет по одному входу и выходу, которые обычно изображаются на противоположных сторонах;
- каждому правилу соответствует своя графическая диаграмма, на которой терминалы и нетерминалы соединяются посредством дуг;
- альтернативы в правилах задаются ветвлением дуг, а итерации - их слиянием;
- должна быть одна входная дуга (располагается обычно слева или сверху), задающая начало правила и помеченная именем определяемого нетерминала, и одна выходная, задающая его конец (обычно располагается справа и снизу);
- стрелки на дугах диаграмм обычно не ставятся, а направления связей отслеживаются движением от начальной дуги в соответствии с плавными изгибами промежуточных дуг и ветвлений.
Пример 1.4. Описание синтаксиса модельного языка М с помощью диа
Описание синтаксиса модельного языка М с помощью диаграмм Вирта представлено на рисунке 1.2.
цифра
буква
идентификатор
число
ключевое_слово
разделитель
программа
описание
тело
оператор
присваивания
условный
цикла
составной
ввода
вывода
выражение
сумма
произведение
операнд
логическая_константа
Пример 1.4. Программа на модельном языке М, вычисляющая среднее арифметическое чисел, введенных с клавиатуры.
program
var k, n, sum: int;
begin
read(n);
sum:= 0;
i:=1;
while i<=n do
begin
read(k);
sum:=sum+k;
k:=k+1
end;
write(sum/n)
end.
2. Общая структура компилятора
Определение 2.1. Компилятор – это программа, которая осуществляет перевод исходной программы на входном языке в эквивалентную ей объектную программу на языке машинных команд или языке ассемблере.
Основные функции компилятора:
1) проверка исходной цепочки символов на принадлежность к входному языку;
2) генерация выходной цепочки символов на языке машинных команд или ассемблере.
Процесс компиляции состоит из двух основных этапов: синтеза и анализа. На этапе анализа выполняется распознавание текста исходной программы и заполнение таблиц идентификаторов. Результатом этапа служит некоторое внутреннее представление программы, понятное компилятору.
На этапе синтеза на основании внутреннего представления программы и информации, содержащейся в таблице идентификаторов, порождается текст результирующей программы. Результатом этого этапа является объектный код.
Данные этапы состоят из более мелких стадий, называемых фазами. Состав фаз и их взаимодействие зависит от конкретной реализации компилятора. Но в том или ином виде в каждом компиляторе выделяются следующие фазы:
- лексический анализ;
- синтаксический анализ;
- семантический анализ;
- подготовка к генерации кода;
- генерация кода.
Определение 2.2. Процесс последовательного чтения компилятором данных из внешней памяти, их обработки и помещения результатов во внешнюю память, называется проходом компилятора.
По количеству проходов выделяют одно-, двух-, трех- и многопроходные компиляторы. В данном пособии предлагается схема разработки трехпроходного компилятора, в котором первый проход – лексический анализ, второй - синтаксический, семантический анализ и генерация внутреннего представления программы, третий – интерпретация программы.
Общая схема работы компилятора представлена на рисунке 2.1.
Рисунок 2.1 – Общая схема работы компилятора
3. Лексический анализатор программы
Определение 3.1. Лексический анализатор (ЛА) – это первый этап процесса компиляции, на котором символы, составляющие исходную программу, группируются в отдельные минимальные единицы текста, несущие смысловую нагрузку – лексемы.
Задача лексического анализа - выделить лексемы и преобразовать их к виду, удобному для последующей обработки. ЛА использует регулярные грамматики.
ЛА необязательный этап компиляции, но желательный по следующим причинам:
1) замена идентификаторов, констант, ограничителей и служебных слов лексемами делает программу более удобной для дальнейшей обработки;
2) ЛА уменьшает длину программы, устраняя из ее исходного представления несущественные пробелы и комментарии;
3) если будет изменена кодировка в исходном представлении программы, то это отразится только на ЛА.
В процедурных языках лексемы обычно делятся на классы:
- служебные слова;
- ограничители;
- числа;
- идентификаторы.
Каждая лексема представляет собой пару чисел вида (n, k), где n – номер таблицы лексем, k - номер лексемы в таблице.
Входные данные ЛА - текст транслируемой программы на входном языке.
Выходные данные ЛА - файл лексем в числовом представлении.
Пример 3.1. Для модельного языка М таблица служебных слов будет иметь вид:
1) program; 2) var; 3) int; 4) bool; 5) begin; 6) end; 7) if; 8) then; 9) else; 10) while; 11) do; 12) read; 13) write; 14) true; 15) false.
Таблица ограничителей содержит:
1) . ; 2) ; ; 3) , ; 4) : ; 5) := ; 6) (; 7) ) ; 8) + ; 9) - ; 10) * ; 11) / ; 12) ; 13) ; 14) ; 15) = ; 16) > ; 17) <.
Таблицы идентификаторов и чисел формируются в ходе лексического анализа.
Пример 1.6. Описать результаты работы лексического анализатора для модельного языка М.
Входные данные ЛА: program var k, sum: int; begin k:=0;…
Выходные данные ЛА: (1, 1) (1, 2) (4, 1) (2, 3) (4, 2) (2, 4) (1, 3) (2, 2) (1, 5) (4, 1) (2, 5) (3, 1) (2, 2)…
Анализ текста проводится путем разбора по регулярным грамматикам и опирается на способ разбора по диаграмме состояний, снабженной дополнительными пометками-действиями. В диаграмме состояний с действиями каждая дуга имеет вид, представленный на рисунке 2.4. Смысл этой конструкции: если текущим является состояние А и очередной входной символ совпадает с для какого либо i, то осуществляется переход в новое состояние В, при этом выполняются действия D1, D2, …, Dm.
Для удобства разбора вводится дополнительное состояние диаграммы ER, попадание в которое соответствует появлению ошибки в алгоритме разбора. Переход по дуге, не помеченной ни одним символом, осуществляется по любому другому символу, кроме тех, которыми помечены все другие дуги, выходящие из данного состояния.
Рисунок 3.1 – Дуга ДС с действиями
Алгоритм 3.1. Разбор цепочек символов по ДС с действиями
Шаг 1. Объявляем текущим начальное состояние ДС H.
Шаг 2. До тех пор, пока не будет достигнуто состояние ER или конечное состояние ДС, считываем очередной символ анализируемой строки и переходим из текущего состояния ДС в другое по дуге, помеченной этим символом, выполняя при этом соответствующие действия. Состояние, в которое попадаем, становится текущим.
ЛА строится в два этапа:
1) построить ДС с действиями для распознавания и формирования внутреннего представления лексем;
2) по ДС с действиями написать программу сканирования текста исходной программы.
Пример 3.2. Составим ЛА для модельного языка М. Предварительно введем следующие обозначения для переменных, процедур и функций.
Переменные:
1) СН – очередной входной символ;
2) S - буфер для накапливания символов лексемы;
3) B – переменная для формирования числового значения константы;
4) CS - текущее состояние буфера накопления лексем с возможными значениями: Н - начало, I - идентификатор, N - число, С - комментарий, DV – двоеточие, О - ограничитель, V - выход, ER –ошибка;
- t - таблица лексем анализируемой программы с возможными значениями: TW - таблица служебных слов М-языка, TL – таблица ограничителей М-языка, TI - таблица идентификаторов программы, TN – чисел, используемых в программе;
6) z - номер лексемы в таблице t (если лексемы в таблице нет, то z=0).
Процедуры и функции:
1) gc – процедура считывания очередного символа текста в переменную СН;
2) let – логическая функция, проверяющая, является ли переменная СН буквой;
3) digit - логическая функция, проверяющая, является ли переменная СН цифрой;
4) nill – процедура очистки буфера S;
5) add – процедура добавления очередного символа в конец буфера S;
6) look(t) – процедура поиска лексемы из буфера S в таблице t с возвращением номера лексемы в таблице;
7) put(t) – процедура записи лексемы из буфера S в таблицу t, если там не было этой лексемы, возвращает номер данной лексемы в таблице;
8) out(n, k) – процедура записи пары чисел (n, k) в файл лексем.
Шаг 1. Построим ДС с действиями для распознавания и формирования внутреннего представления лексем модельного языка М (рисунок 2.5).
Рисунок 3.2 – Диаграмма состояний с действиями для модельного языка М
Шаг 2. Составляем функцию scanner для анализа текста исходной программы:
function scanner: boolean;
var CS: (H, I, N, C, DV, O, V, ER);
begin gc; CS:=H;
repeat
case CS of
H: if CH=’ ‘ then gc
else
if let then
begin
nill; add;
gc; CS:= I
end
else
if digit then
begin
B:=ord(CH)-ord(‘0’);
gc; CS:= N
end
else
if CH= ‘:’ then
begin
gc;
CS:= DV
end
else
if CH=’.’ then
begin
out(2,1);
CS:=V
end
else
if CH=’{‘ then
begin
gc; CS:=C
end
else CS:=O;
I: if let or digit then
begin
add; gc
end
else begin
look(TW);
if z<>0 then
begin
out(1,z); CS:=H
end
else begin
put(TI);
out(4,z);
CS:=H
end
end;
N: if digit then
begin
B:=10*B+ord(CH)-ord(‘0’);
gc
end
else begin
put(TN);
out(3,z); CS:=H
end;
C: if CH=’}’ then begin
gc; CS:=H
end
else if CH=’.’ then CS:=ER else gc;
DV: if CH=’=’ then begin
gc; out(2,5);
CS:=H
end
else begin
out(2,4); CS:=H
end;
O: begin
null; add; look(TL);
if z<>0 then begin
gc; out(2,z);
CS:=H
end
else CS:=ER
end
end {case}
until (CS=V) or (CS=ER);
scanner:= CS=V
end;
4. Синтаксический анализатор программы
Задача синтаксического анализатора (СиА) - провести разбор текста программы, сопоставив его с эталоном, данным в описании языка. Для синтаксического разбора используются контекстно-свободные грамматики (КС-грамматики).
Один из эффективных методов синтаксического анализа – метод рекурсивного спуска. В основе метода рекурсивного спуска лежит левосторонний разбор строки языка. Исходной сентенциальной формой является начальный символ грамматики, а целевой – заданная строка языка. На каждом шаге разбора правило грамматики применяется к самому левому нетерминалу сентенции. Данный процесс соответствует построению дерева разбора цепочки сверху вниз (от корня к листьям).
Пример 4.1. Дана грамматика с правилами . Требуется выполнить анализ строки cabca.
Левосторонний вывод цепочки имеет вид:
.
Нисходящее дерево разбора цепочки представлено на рисунке 2.6.
Рисунок 4.1 – Дерево нисходящего разбора цепочки cabca
Метод рекурсивного спуска реализует разбор цепочки сверху вниз следующим образом. Для каждого нетерминального символа грамматики создается своя процедура, носящая его имя. Задача этой процедуры – начиная с указанного места исходной цепочки, найти подцепочку, которая выводится из этого нетерминала. Если такую подцепочку считать не удается, то процедура завершает свою работу вызовом процедуры обработки ошибок, которая выдает сообщение о том, что цепочка не принадлежит языку грамматики и останавливает разбор. Если подцепочку удалось найти, то работа процедуры считается нормально завершенной и осуществляется возврат в точку вызова. Тело каждой такой процедуры составляется непосредственно по правилам вывода соответствующего нетерминала, при этом терминалы распознаются самой процедурой, а нетерминалам соответствуют вызовы процедур, носящих их имена.
Пример 4.2. Построим синтаксический анализатор методом рекурсивного спуска для грамматики из примера 2.8.
Введем следующие обозначения:
- СH – текущий символ исходной строки;
- gc – процедура считывания очередного символа исходной строки в переменную СH;
- Err - процедура обработки ошибок, возвращающая по коду соответствующее сообщение об ошибке.
С учетом введенных обозначений, процедуры синтаксического разбора будут иметь вид.
procedure S;
begin
A; B;
if CH<> then ERR
end;
procedure A;
begin
if CH=a then gc
else if CH=c
then begin
gc; A
end
else Err
end;
procedure B;
begin
if CH= b then
begin
gc; B
end
else Err
end;
Теорема 4.1. Достаточные условия применимости метода рекурсивного спуска
Метод рекурсивного спуска применим к грамматике, если правила вывода грамматики имеют один из следующих видов:
1) A, где (TN)*, и это единственное правило вывода для этого нетерминала;
2) Aa11 | a22 |…| ann, где ai T для каждого i=1, 2,…, n; aiaj для ij, i(TN)*, т.е. если для нетерминала А несколько правил вывода, то они должны начинаться с терминалов, причем эти терминалы должны быть различными.
Данные требования являются достаточными, но не являются необходимыми. Можно применить эквивалентные преобразования КС-грамматик, которые способствуют приведению грамматики к требуемому виду, но не гарантируют его достижения (см. лабораторную работу № 4) /11/.
При описании синтаксиса языков программирования часто встречаются правила, которые задают последовательность однотипных конструкций, отделенных друг от друга каким-либо разделителем. Общий вид таких правил:
La | a,L или в сокращенной форме La{,a}.
Формально здесь не выполняются условия метода рекурсивного спуска, т.к. две альтернативы начинаются одинаковыми терминальными символами. Но если принять соглашения, что в подобных ситуациях выбирается самая длинная подцепочка, выводимая из нетерминала L, то разбор становится детерминированным, и метод рекурсивного спуска будет применим к данному правилу грамматики. Соответствующая правилу процедура будет иметь вид:
procedure L;
begin
if CH<>’a’ then Err else gc;
while CH=’,’ do
begin
gc;
if CH<>’a’ then Err else gc
end
end;
Пример 4.3. Построим синтаксический анализатор методом рекурсивного спуска для модельного языка М.
Вход – файл лексем в числовом представлении.
Выход – заключение о синтаксической правильности программы или сообщение об имеющихся ошибках.
Введем обозначения:
1) LEX – переменная, содержащая текущую лексему, считанную из файла лексем;
2) gl – процедура считывания очередной лексемы из файла лексем в переменную LEX;
2) EQ(S) – логическая функция, проверяющая, является ли текущая лексема LEX лексемой для S;
3) ID – логическая функция, проверяющая, является ли LEX идентификатором;
- NUM - логическая функция, проверяющая, является ли LEX числом.
Процедуры, проверяющие выполнение правил, описывающих язык М и составляющие синтаксический анализатор, будут иметь следующий вид:
1) для правила Р program D1 В.
procedure Р;
begin
if EQ(`program`) then gl else ERR;
D1;
B;
if not EQ(‘.’) then ERR
end;
2) для правила D1 var D{;D}
procedure D1;
begin
if EQ(‘var’) then gl else ERR;
D;
while EQ(‘;’) do
begin
gl; D
end
end;
3) для правила D I{,I}:(int | bool)
procedure D;
begin
I;
while EQ(‘,’) do
begin
gl; I
end;
if EQ(‘:’) then gl else ERR;
if EQ(‘int’) or EQ(‘bool’) then gl else ERR
end;
4) для правила F I|N|L| F|(E)
procedure F;
begin
if ID or NUM or EQ(‘true’) or EQ(‘false’) then gl
else
if EQ(‘’)
then begin
gl; F
end
else
if EQ(‘(‘)
then begin
gl; E;
if EQ(‘)’) then gl else ERR
end
else ERR
end;
Аналогично составляются оставшиеся процедуры.
5. Семантический анализатор программы
В ходе семантического анализа проверяются отдельные правила записи исходных программ, которые не описываются КС-грамматикой. Эти правила носят контекстно-зависимый характер, их называют семантическими соглашениями или контекстными условиями.
Рассмотрим пример построения семантического анализатора (СеА) для программы на модельном языке М. Соблюдение контекстных условий для языка М предполагает три типа проверок:
1) обработка описаний;
2) анализ выражений;
3) проверка правильности операторов.
В оптимизированном варианте СиА и СеА совмещены и осуществляются параллельно. Поэтому процедуры СеА будем внедрять в ранее разработанные процедуры СиА.
Вход: файл лексем в числовом представлении.
Выход: заключение о семантической правильности программы или о типе обнаруженной семантической ошибки.
Обработка описаний
Задача обработки описаний - проверить, все ли переменные программы описаны правильно и только один раз. Эта задача решается следующим образом.
Таблица идентификаторов, введенная на этапе лексического анализа, расширяется, приобретая вид таблицы 5.1. Описание таблицы идентификаторов будет иметь вид:
type
tabid = record
id :string;
descrid :byte;
typid :string[4];
addrid :word
end;
var
TI: array[1.. n] of tabid;
Таблица 5.1 – Таблица идентификаторов на этапе СеА
|
Номер
|
Идентификатор
|
Описан
|
Тип
|
Адрес
|
|
1
|
K
|
1
|
Int
|
…
|
|
2
|
Sum
|
0
|
…
|
…
|
Поле «описан» таблицы на этапе лексического анализа заполняется нулем, а при правильном описании переменных на этапе семантического анализа заменяется единицей.
При выполнении процедуры D вводится стековая переменная-массив, в которую заносится контрольное число 0. По мере успешного выполнения процедуры I в стек заносятся номера считываемых из файла лексем, под которыми они записаны в таблице идентификаторов. Как только при считывании лексем встречается лексема «:», из стека извлекаются записанные номера и по ним в таблице идентификаторов проставляется 1 в поле «описан» (к этому моменту там должен быть 0). Если очередная лексема будет «int» или «bool», то попутно в таблице идентификаторов поле «тип» заполняется соответствующим типом.
Пример 5.1. Пусть фрагмент описания на модельном языке имеет вид: var k, sum: int … Тогда соответствующий фрагмент файла лексем: (1, 2) (4, 1) (2, 3) (4, 2)…Содержимое стека при выполнении процедуры D представлено на рисунке 2.7.
Рисунок 5.1 – Содержимое стека при выполнении процедуры D
Для реализации обработки описаний введем следующие обозначения переменных и процедур:
1) LEX – переменная, хранящая значение очередной лексемы, представляющая собой одномерный массив размером 2, т.е. для лексемы (n, k) LEX[1]=n, LEX[2]=k;
2) gl – процедура считывания очередной лексемы в переменную LEX;
3) inst(l) - процедура записи в стек числа l;
4) outst(l) – процедура вывод из стека числа l;
5) instl – процедура записи в стек номера, под которым лексема хранится в таблице идентификаторов, т.е. inst(LEX[2]);
6) dec(t) - процедура вывода всех чисел из стека и вызова процедуры decid(1, t);
7) decid(l, t) – процедура проверки и заполнения поля «описан» и «тип» таблицы идентификаторов для лексемы с номером l и типа t.
Процедуры dec и decid имеют вид:
procedure decid (l:..; t:...);
begin
if TI[l].descrid =1 then ERR
else begin
TI[l].descrid: = 1;
TI[l].typid:= t
end
end;
procedure dec(t: ...);
begin
outst(l);
while l<>0 do
begin
decid(l, t);
outst(l)
end
end;
Правило и процедура D с учетом семантических проверок принимают вид:
D <inst(0)> I <instl> {, I <instl> } : ( int <deс(‘int’)> | bool <dec(‘bool’)> )
procedure D;
begin
inst(0);
I;
instl;
while EQ(‘,’) do
begin
gl; I; instl
end;
if EQ(‘:’) then gl else ERR;
if EQ(‘int’) then
begin
gl; dec(‘int’)
end
else
if EQ(‘bool’)
then
begin
gl; dec(‘bool’)
end
else ERR
end;
Анализ выражений
Задача анализа выражений - проверить описаны ли переменные, встречающиеся в выражениях, и соответствуют ли типы операндов друг другу и типу операции.
Эти задачи решаются следующим образом. Вводится таблица двуместных операций (таблица 5.1) и стек, в который в соответствии с разбором выражения E заносятся типы операндов и знак операции. После семантической проверки в стеке оставляется только тип результата операции. В результате разбора всего выражения в стеке остается тип этого выражения.
Для реализации анализа выражений введем следующие обозначения процедур и функций:
1) checkid - процедура, которая для лексемы LEX, являющейся идентификатором, проверяет по таблице идентификаторов TI, описан ли он, и, если описан, то помещает его тип в стек;
2) checkop – процедура, выводящая из стека типы операндов и знак операции, вызывающая процедуру gettype(op, t1, t2, t), проверяющая соответствие типов и записывающая в стек тип результата операции;
3) gettype(ор, t1, t2, t) – процедура, которая по таблице операций TOP для операции ор выдает тип t результата и типы t1, t2 операндов;
4) checknot – процедура проверки типа для одноместной операции «».
Таблица 5.2 – Фрагмент таблицы двуместных операций TOP
|
Операция
|
Тип 1
|
Тип 2
|
Тип результата
|
|
+
>
…
|
int
int
…
|
int
int
…
|
int
bool
…
|
Перечисленные процедуры имеют следующий вид:
procedure checkid;
begin
k:=LEX[2];
if TI[k].descrid = 0 then ERR;
inst(TI[k].typid)
end;
procedure checkop;
begin
outst(top2); outst(op); outst(top1);
gettype(op, t1, t2, t);
if (top1<>t1) or (top2<>t2) then ERR;
inst(t)
end;
procedure checknot;
begin
outst(t);
if t<> bool then ERR;
inst(t)
end;
Правила, описывающие выражения языка М, расширенные процедурами семантического анализа, принимают вид.
Е Е1 {( > | < | = ) <instl> E1 <checkop>}
E1 Т {(+ | - | ) <instl> T <checkop>}
T F {( * | / | ) <instl> F<checkop>}
F I <checkid>| N<inst(‘int’)> | L <inst(‘bool’)>| F <checknot>|(E)
Пример 5.2. Дано выражение a+5*b. Дерево разбора выражения и динамика содержимого стека представлены на рисунке 5.2.
Рисунок 5.2 – Анализ выражения a+5*b
Проверка правильности операторов
Задачи проверки правильности операторов:
1) выяснить, все ли переменные, встречающиеся в операторах, описаны;
2) установить соответствие типов в операторе присваивания слева и справа от символа «:=»;
3) определить, является ли выражение Е в операторах условия и цикла булевым.
Данные задачи решаются путем включения в правило S ранее рассмотренной процедуры checkid, а также новых процедур eqtype и eqbool, имеющих следующий вид:
procedure eqtype;
begin
outst(t2); outst(t1);
if t1<>t2 then ERR
end;
procedure eqbool;
begin
outst(t);
if t<>bool then ERR
end;
Правило S с учетом процедур СеА примет вид:
S I <checkid> := E <eqtype> | if E <eqbool> then S else S
while E <egbool> do S | write (E) | read (I <checkid> )
6. Генерация внутреннего представления программы
Результатом СиА должно быть некоторое внутреннее представление исходной цепочки лексем, которое отражает ее синтаксическую структуру. Программа в таком виде может либо транслироваться в объектный код, либо интерпретироваться.
Выделяют следующие общепринятые способы внутреннего представления программы:
- постфиксная запись;
- многоадресный код с явно именуемым результатом (тетрады);
- многоадресный код с неявно именуемым результатом (триады);
- синтаксические деревья;
- машинные команды или ассемблерный код.
В качестве языка для представления промежуточной программы выберем постфиксную запись – ПОЛИЗ (польская инверсная запись).
Перевод в ПОЛИЗ выражений
В ПОЛИЗе операнды записаны слева направо в порядке использования. Знаки операций следуют таким образом, что знаку операции непосредственно предшествуют его операнды.
Пример 6.1. Для выражения в обычной (инфиксной записи) a*(b+c)-(d-e)/f ПОЛИЗ будет иметь вид: abc+*de-f/-.
Справедливы следующие формальные определения.
Определение 6.1. Если Е является единственным операндом, то ПОЛИЗ выражения Е – это этот операнд.
Определение 6.2. ПОЛИЗ выражения Е1 Е2, где - знак бинарной операции, Е1 и Е2 – операнды для , является запись , где - ПОЛИЗ выражений Е1 и Е2 соответственно.
Определение 6.3. ПОЛИЗ выражения Е, где - знак унарной операции, а Е – операнд , есть запись , где - ПОЛИЗ выражения Е.
Определение 6.4. ПОЛИЗ выражения (Е) есть ПОЛИЗ выражения Е.
Перевод в ПОЛИЗ операторов
Каждый оператор языка программирования может быть представлен как n-местная операция с семантикой, соответствующей семантике оператора.
Оператор присваивания I:=E в ПОЛИЗе записывается:
IE:=,
где «:=» - двуместная операция,
I, E – операнды операции присваивания;
I – означает, что операндом операции «:=» является адрес переменной I, а не ее значение.
Пример 6.2. Оператор x:=x+9 в ПОЛИЗе имеет вид: x x 9 + :=.
Оператор перехода в терминах ПОЛИЗа означает, что процесс интерпретации необходимо продолжить с того элемента ПОЛИЗа, который указан как операнд операции перехода. Чтобы можно было ссылаться на элементы ПОЛИЗа, будем считать, что все они пронумерованы, начиная с единицы (например, последовательные элементы одномерного массива). Пусть ПОЛИЗ оператора, помеченного меткой L, начинается с номера p, тогда оператору безусловного перехода goto L в ПОЛИЗе будет соответствовать:
p!, где ! – операция выбора элемента ПОЛИЗа, номер которого равен p.
Условный оператор. Введем вспомогательную операцию – условный переход «по лжи» с семантикой if (not B) then goto L. Это двуместная операция с операндами B и L. Обозначим ее !F, тогда в ПОЛИЗе она будет записываться:
B p !F, где p – номер элемента, с которого начинается ПОЛИЗ оператора, помеченного меткой L.
С использованием введенной операции условный оператор if B then S1 else S2 в ПОЛИЗе будет записываться:
B p1 !F S1 p2 ! S2, где p1 – номер элемента, с которого начинается ПОЛИЗ оператора S2, а p1 – оператора, следующего за условным оператором.
Пример 6.3. ПОЛИЗ оператора if x>0 then x:=x+8 else x:=x-3 представлен в таблице 6.1.
Таблица 6.1 – ПОЛИЗ оператора if
|
лексема
|
x
|
0
|
>
|
13
|
!F
|
x
|
x
|
8
|
+
|
:=
|
18
|
!
|
x
|
x
|
3
|
-
|
:=
|
…
|
|
номер
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
16
|
17
|
18
|
Оператор цикла. С учетом введенных операций оператор цикла while B do S в ПОЛИЗе будет записываться:
B p1 !F S po !, где po – номер элемента, с которого начинается ПОЛИЗ выражения B, а p1 – оператора, следующего за данным оператором цикла.
Операторы ввода и вывода языка М одноместные. Пусть R – обозначение операции ввода, а W – обозначение операции вывода, тогда оператор read(I) в ПОЛИЗе запишется как I R, а оператор write(E) – E W.
Составной оператор begin S1; S2;...; Sn end в ПОЛИЗе записывается как S1 S2... Sn.
Пример 6.4. ПОЛИЗ оператора while n>3 do begin write(n*n-1); n:=n-1 end представлен в таблице 6.2.
Таблица 6.2 – ПОЛИЗ оператора while
|
лексема
|
n
|
3
|
>
|
19
|
!F
|
n
|
n
|
*
|
1
|
-
|
W
|
n
|
n
|
1
|
-
|
:=
|
1
|
!
|
…
|
|
номер
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
16
|
17
|
18
|
19
|
Синтаксически управляемый перевод
На практике СиА, СеА и генерация внутреннего представления программы осуществляется часто одновременно. Способ построения промежуточной программы – синтаксически управляемый перевод. В его основе лежит грамматика с действиями. Параллельно с анализом исходной цепочки лексем осуществляются действия по генерации внутреннего представления программы. Для этого грамматика дополняется вызовами соответствующих процедур.
Пример 6.5. Составим процедуры перевода в ПОЛИЗ программы на М языке.
ПОЛИЗ представляет собой массив, каждый элемент которого является парой вида (n, k), где n – номер таблицы лексем, k – номер лексемы в таблице. Расширяем набор лексем:
1) в таблицу ограничителей добавляем новые операции ! (18), !F (19), R (20), W (21);
2) для ссылок на номера элементов ПОЛИЗа введем нулевую таблицу лексем, т.е. пара (0, p) - это лексема, обозначающая p-ый элемент в ПОЛИЗе;
3) чтобы различать операнды-переменные и операнды-адреса переменных, обозначим переменные как четвертую таблицу лексем, а адреса – пятую.
Введем следующие обозначения переменных и процедур:
1) Р – переменная–массив, в который размещается генерируемая программа;
2) free – переменная, хранящая номер первого свободного элемента в массиве P;
3) LEX – переменная, хранящая очередную лексему;
4) put_lex(LEX) – запись очередной лексемы в массив P, т.е. P[free]:=LEX и free:=free+1;
5) put_l – запись текущей лексемы в массив P;
6) put_l5 – запись текущей лексемы в массив P с изменением четвертого класса лексем на пятый;
7) put_op - запись в массив P знака операции, считанного процедурой checkop;
8) make(k) - процедура, формирующая лексему-метку (0, k).
Правила, описывающие выражения языка М, с учетом действий перевода в ПОЛИЗ принимают вид.
Е Е1 {( > | < | = ) <instl> E1 <checkop; put_op >}
E1 Т {(+ | - | ) <instl> T <checkop; put_op >}
T F {( * | / | ) <instl> F<checkop; put_op >}
F I <checkid; put_l> | N <inst(‘int’); put_l> | L <inst(‘bool’); put_l>|
F <checknot; put_lex(‘’)>| (E)
Оператор присваивания, дополненный действиями, примет вид:
S I <checkid; put_l5> := E <eqtype; put_lex(‘:=’)>
При генерации ПОЛИЗа выражений и оператора присваивания элементы массива Р записываются последовательно. Семантика условного оператора такова, что значения операндов для операций безусловного перехода и перехода «по лжи» в момент генерации еще не неизвестны. Поэтому необходимо запоминать номера элементов массива Р, соответствующих этим операндам, а затем, когда станут известны их значения, заполнять пропущенное.
Правила условного оператора и оператора цикла примут вид:
S if E <egbool; p1:=free; free:=free+1; put_lex(‘!F’)> then S <p2:=free; free:=free+1; put_lex(‘!’); P[p1]:=make(free)> else S <P[p2]:=make(free)>
S while <p0:=free> E <egbool; p1:=free; free:=free+1; put_lex(‘!F’)> do S <P[free]:=make(p0); put_lex(‘!’); P[p1]:=make(free) >
Правила операторов ввода и вывода с учетом действий записи в ПОЛИЗ будут преобразованы следующим образом:
S write (E <put_lex(‘W’)>) | read (I <checkid; put_l5; put_lex(‘R’)> )
Чтобы в конце ПОЛИЗа была точка, правило Р переписывается в виде:
Pprogram D1 B <put_lex(‘.’)>.
Таким образом, польская инверсная запись очищена от всех служебных слов, кроме true и false; от ограничителей остаются только знаки операций и знаки «:=», «.».
7. Интерпретатор программы
Запись программы в форме ПОЛИЗа удобна для последующей интерпретации (выполнения программы) с помощью стека. Массив ПОЛИЗа просматривается один раз слева направо, при этом:
1) если очередной элемент ПОЛИЗа является операндом, то его значение заносят в стек;
2) если очередной элемент – операция, то на «верхушке» стека находятся ее операнды, которые извлекаются из стека, над ними выполняется соответствующая операция, результат которой заносится в стек;
3) интерпретация продолжается до тех пор, пока не будет считана из ПОЛИЗа точка, стек при этом должен быть пуст.
Пример7.1. Интерпретировать ПОЛИЗ программы, заданный таблицей 7.1 при введенном значении а, равном 7.
Таблица 7.1 – ПОЛИЗ исходной программы
Лексема
|
a
|
r
|
a
|
5
|
>
|
17
|
!F
|
b
|
a
|
3
|
+
|
(n, k)
|
(5,1)
|
(2,20)
|
(4,1)
|
(3,1)
|
(2,16)
|
(0,17)
|
(2,19)
|
(5,1)
|
(4,1)
|
(3,2)
|
(2,8)
|
|
Номер
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
Продолжение таблицы 7.1 – ПОЛИЗ исходной программы
Лексема
|
:=
|
b
|
W
|
19
|
!
|
a
|
W
|
.
|
(n, k)
|
(2,5)
|
(4,1)
|
(2,21)
|
(0,19)
|
(2,18)
|
(4,1)
|
(2,21)
|
(2,1)
|
|
Номер
|
12
|
13
|
14
|
15
|
16
|
17
|
18
|
19
|
Процесс интерпретации программы на модельном языке М, записанной в форме ПОЛИЗа, показан в таблице 7.2.
Таблица 7.2 – Ход интерпретации ПОЛИЗа программы
Стек
|
Текущий элемент ПОЛИЗа
|
Операция
|
Таблицы
переменных
|
|
|
|
|
адреса
|
значения
|
|
пуст
|
1
|
адрес - в стек
|
1) a
2) b
|
1) -
2) -
|
|
1
|
2
|
извлечь из стека номер элемента таблицы значений и записать по нему число 7
|
1) a
2) b
|
1) 7
2) -
|
|
пуст
|
3
|
значение - в стек
|
1) a
2) b
|
1) 7
2) -
|
|
7
|
4
|
значение - в стек
|
1) a
2) b
|
1) 7
2) -
|
|
7; 5
|
5
|
в стек – true, т.к. 7>5
|
1) a
2) b
|
1) 7
2) -
|
Стек
|
Текущий элемент ПОЛИЗа
|
Операция
|
Таблицы
переменных
|
|
|
|
|
адреса
|
значения
|
|
true
|
6
|
метка - в стек
|
1) a
2) b
|
1) 7
2) -
|
|
true; 6
|
7
|
переход, к следующему элементу
ПОЛИЗа, т.к. условие истинно
|
1) a
2) b
|
1) 7
2) -
|
|
пуст
|
8
|
адрес - в стек
|
1) a
2) b
|
1) 7
2) -
|
|
2
|
9
|
значение переменной - в стек
|
1) a
2) b
|
1) 7
2) -
|
|
2; 7
|
10
|
число - в стек
|
1) a
2) b
|
1) 7
2) -
|
|
2; 7; 3
|
11
|
извлечь из стека 3 и 7 и поместить в стек их сумму
|
1) a
2) b
|
1) 7
2) -
|
|
2; 10
|
12
|
присвоить второму элементу таблицы значений число 10
|
1) a
2) b
|
1) 7
2) 10
|
|
пуст
|
13
|
значение – в стек
|
1) a
2) b
|
1) 7
2) 10
|
|
10
|
14
|
вывести на экран число из «верхушки стека»
|
1) a
2) b
|
1) 7
2) 10
|
|
пуст
|
15
|
метка – в стек
|
1) a
2) b
|
1) 7
2) 10
|
|
19
|
16
|
переход к элементу ПОЛИЗ с номером, извлекаемым из верхушки стека
|
1) a
2) b
|
1) 7
2) 10
|
|
пуст
|
19
|
интерпретация завершена
|
1) a
2) b
|
1) 7
2) 10
|
Пример 7.2. Построим интерпретатор ПОЛИЗа для языка М.
Введем следующие обозначения процедур и функций:
1) addr(1) – функция, выдающая адрес ячейки, отведенной для хранения лексемы l;
2) cont(А) – функция, выдающая содержимое ячейки с адресом А;
3) let(А, х) – процедура записи в ячейку с адресом А значения х;
4) inst(x) – процедура записи в стек значения х;
5) outst(x) – процедура считывания из стека значения х.
Тело интерпретатора ПОЛИЗа будет иметь следующий вид:
free:=1; {на начало P}
repeat
LEX:=P[free]; {очередная лексема}
n:=LEX[1]; k:=LEX[2];
case n of
0: inst(k); {метка - в стек}
5: inst(addr(LEX)); {адрес - в стек}
1,3,4: inst(cont(addr(LEX))); {значение - в стек}
2: {знак операции}
case k of
8{+}: begin outst(у); outst(x); inst(x+y) end;
9{-}: begin outst(у); outst(x); inst(x-y) end;
…{аналогично для *, / и других операций}
14{}: begin outst(x); inst(not x) end;
5{:=} begin outst(x); outst(А); let(А, х) end;
18{!}: begin outst(free); free:=free-1 end;
19{!F}: begin
outst(free1); outst(B);
if B=false then free:=free1-1;
end;
20{R}: begin outst(A); read(x); let(А, х) end;
21{W}: begin outst(x); write(x) end
end
end
free:=free+1;
until (k=2) and (n=2);
1) 2) 3)
 INCLUDEPICTURE "../../../../../Мои%20документы/трансляторы/10.files/fig02-01.gif" \* MERGEFORMAT
INCLUDEPICTURE "../../../../../Мои%20документы/трансляторы/10.files/fig02-01.gif" \* MERGEFORMAT 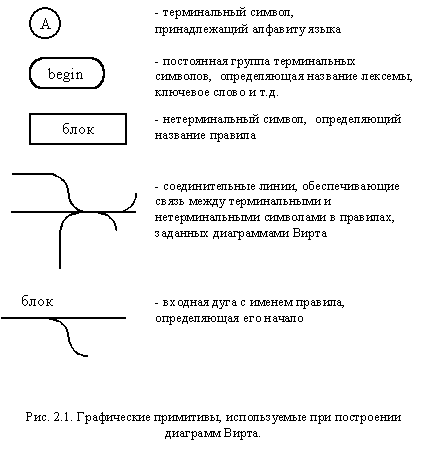
1) – терминальный символ, принадлежащий алфавиту языка;
2) – постоянная группа терминальных символов, определяющая название лексемы, ключевое слово и т.д.;
3) – нетерминальный символ, определяющий название правила;
4) – входная дуга с именем правила, определяющая его название;
5) – соединительные линии, обеспечивающие связь между терминальными и нетерминальными символами в правилах.
Рисунок 1.1 – Графические примитивы диаграмм Вирта
блок
А
begin
4)
5)
8
3
7
2
6
9
4
5
0
1
D1, D2, …, Dm
g
a
b
c
d
e
v
t
w
h
i
j
k
l
m
n
o
u
p
q
r
s
x
y
z
f
буква
цифра
буква
цифра
program
var
begin
end
int
bool
read
write
if
then
else
while
do
true
false
-
:=
(
*
.
¬
)
/
{
=
,
}
>
;
+
<
:
program
описание
;
тело
.
var
идентификатор
:
int
bool
,
begin
nd
оператор
;
присваивания
условный
цикла
составной
ввода
вывода
идентификатор
выражение
:=
if
then
else
выражение
оператор
оператор
while
do
выражение
оператор
begin
end
оператор
;
read
(
)
идентификатор
write
(
)
выражение
сумма
=
>
<
сумма
произведение
+
-
множитель
*
/
идентификатор
число
логическая_константа
множитель
выражение
(
)
¬
true
false
t1, t2, …, tn
В
А
‘=’
+
‘}’
‘{’
‘.’
‘:’
z0
z0
ER
V
DV
ER
N
C
H
I
let
null, add , gc
digit
B=10*B+’CH’-‘0’, gc
gc
out(2, 1)
gc
gc
‘.’
gc
let or digit
add, gc
look(TW)
out(1, z)
put(TI), out(4, z)
-
digit
B=’CH’-‘0’, gc
out(2, 4)
null, add, look(TL)
-
+
put(TN), out(3, z)
gc, out(2, 5)
A
B
c
A
a
b
A
c
A
a
S
2
1
0
1)
a
b
5
R
N
F
*
2)
F
C
3)
I
F
T
+
T
I
C
Лексический
анализ
Синтаксический разбор
Семантический анализ
Подготовка к
генерации кода
Генерация кода
Внутреннее представление программы
Исходная
программа
Анализ
и локализация
обнаруженных
ошибок
Сообщение об ошибке
Объектная программа
Анализ
Синтез
Таблицы идентификаторов
‘ ‘
gc
gc, out(2, z)
E
E1
блок
Формальные системы и языки программирования