Лингвистическое и программное обеспечение систем
Министерство образования и науки Российской Федерации
Федеральное государственное бюджетное образовательное учреждение высшего профессионального образования
Волгоградский государственный технический университет
Факультет послевузовского образования
Кафедра «Системы автоматизированного проектирования и
поискового конструирования»
Семестровая работа по дисциплине
«Лингвистическое и программное обеспечение систем».
Выполнил:
Группа:
Проверил: Розалиев В.Л.
Волгоград, 2015
Семантические сети.
Семантическая сеть — информационная модель предметной области, имеющая вид ориентированного графа, вершины которого соответствуют объектам предметной области, а дуги (рёбра) задают отношения между ними. Объектами могут быть понятия, события, свойства, процессы. Таким образом, семантическая сеть является одним из способов представления знаний. В названии соединены термины из двух наук: семантика в языкознании изучает смысл единиц языка, а сеть в математике представляет собой разновидность графа — набора вершин, соединённых дугами (рёбрами), которым присвоено некоторое число. В семантической сети роль вершин выполняют понятия базы знаний, а дуги (причем направленные) задают отношения между ними. Таким образом, семантическая сеть отражает семантику предметной области в виде понятий и отношений.
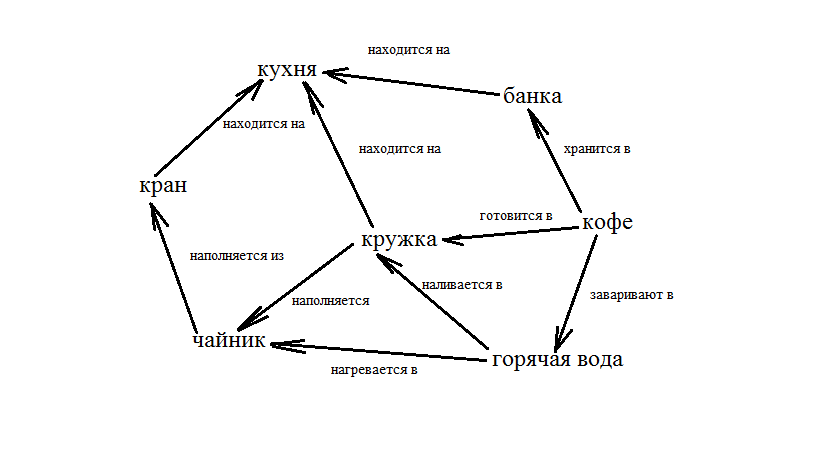
Рисунок 1. Пример семантической сети.
Для всех семантических сетей справедливо разделение по арности и количеству типов отношений.
- По количеству типов отношений, сети могут быть однородными и неоднородными.
- Однородные сети обладают только одним типом отношений (стрелок), например, таковой является вышеупомянутая классификация биологических видов (с единственным отношением AKO).
- В неоднородных сетях количество типов отношений больше двух. Классические иллюстрации данной модели представления знаний представляют именно такие сети. Неоднородные сети представляют больший интерес для практических целей, но и большую сложность для исследования. Неоднородные сети можно представлять как переплетение древовидных многослойных структур. Примером такой сети может быть Семантическая сеть Википедии.
- По арности:
- типичными являются сети с бинарными отношениями (связывающими ровно два понятия). Бинарные отношения очень просты и удобно изображаются на графе в виде стрелки между двух концептов. Кроме того, они играют исключительную роль в математике.
- На практике, однако, могут понадобиться отношения, связывающие более двух объектов — N-арные. При этом возникает сложность — как изобразить подобную связь на графе, чтобы не запутаться. Концептуальные графы снимают это затруднение, представляя каждое отношение в виде отдельного узла.
- По размеру:
- Для решения конкретных задач, например, тех которые решают системы искусственного интеллекта.
- Семантическая сеть отраслевого масштаба должна служить базой для создания конкретных систем, не претендуя на всеобщее значение.
- Глобальная семантическая сеть. Теоретически такая сеть должна существовать, поскольку всё в мире взаимосвязано. Возможно когда-нибудь такой сетью станет Всемирная паутина.
Количество типов отношений в семантической сети определяется её создателем, исходя из конкретных целей. В реальном мире их число стремится к бесконечности. Каждое отношение является, по сути, предикатом, простым или составным. Скорость работы с базой знаний зависит от того, насколько эффективно реализованы программы обработки нужных отношений.
Наиболее часто возникает потребность в описании отношений между элементами, множествами и частями объектов. Отношение между объектом и множеством, обозначающим, что объект принадлежит этому множеству, называется отношением классификации (ISA). Говорят, что множество (класс) классифицирует свои экземпляры. (пример: «Шарик является собакой» = Шарик является объектом типа собака). Иногда это отношение именуют также MemberOf, InstanceOf или подобным образом. Связь ISA предполагает, что свойства объекта наследуются от множества. Обратное к ISA отношение используется для обозначения примеров, поэтому так и называется — «Example», или по-русски «Пример». Иерархические отношения образуют древовидную структуру.
- Отношение между надмножеством и подмножеством (называется AKO — «A Kind Of», «разновидность»). (Пример: «собака является животным» = тип с именем собака является подтипом типа животные). Элемент подмножества называется гипонимом (собака), а надмножества — гиперонимом (животное), а само отношение называется отношением гипонимии. Альтернативные названия — «SubsetOf» и «Подмножество». Это отношение определяет, что каждый элемент первого множества входит и во второе (выполняется ISA для каждого элемента), а также логическую связь между самими подмножествами: что первое не больше второго и свойства первого множества наследуются вторым. Отношение АКО (Род-Вид) часто используется для навигации в информационном пространстве.
- Объект, как правило, состоит из нескольких частей, или элементов. Например, компьютер состоит из системного блока, монитора, клавиатуры, мыши и т. д. Важным отношением является HasPart, описывающее связь частей и целого — отношение меронимии. В этом случае свойства первого множества не наследуются вторым. Мероним и холоним — противоположные понятия:
- Мероним — объект, являющийся частью для другого. (Двигатель — мероним автомобиля.)
- Холоним — объект, который включает в себя другое. (Например, у дома есть крыша. Дом — холоним крыши. Компьютер — холоним монитора.)
Часто в семантических сетях требуется определить отношения синонимии и антонимии. Эти связи либо дублируются явно в самой сети, либо определяются алгоритмической составляющей.
Вспомогательные
В семантических сетях часто используются также следующие отношения:
- функциональные связи (определяемые обычно глаголами «производит», «влияет»…);
- количественные (больше, меньше, равно…);
- пространственные (далеко от, близко от, за, под, над…);
- временные (раньше, позже, в течение…);
- атрибутивные (иметь свойство, иметь значение);
- логические (И, ИЛИ, НЕ);
- лингвистические.
Этот список может сколь угодно продолжаться: в реальном мире количество отношений огромно. Например, между понятиями может использоваться отношение «совершенно разные вещи» или подобное: Не_имеют_отношения_друг_к_другу(Солнце, Кухонный_чайник).
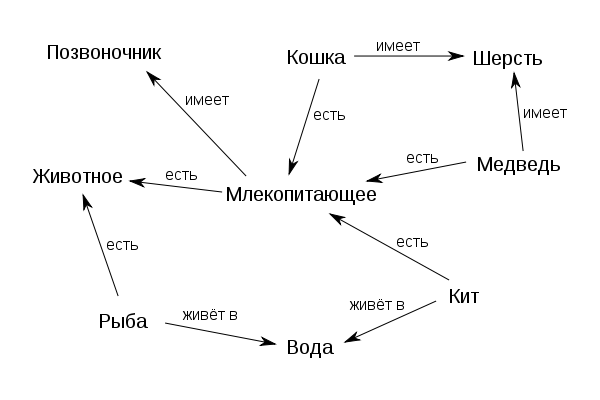
Рисунок 2. Пример семантической сети.
Применение семантических сетей для анализа текста.
Семантические сети используются для анализа текста, в основе которого лежит представление смысла текста в форме ассоциативной семантической сети. Семантическая сеть - это множество понятий (слов и словосочетаний), связанных между собой. В семантическую сеть включаются наиболее часто встречающиеся слова текста, которые несут основную смысловую нагрузку. Для каждого понятия формируется набор ассоциативных (смысловых) связей, т.е. список других понятий, в сочетании с которыми оно встречалось в предложениях текста. При этом считается, что чем чаще встречаются вместе два понятия в предложениях текста, тем выше вероятность того, что они связаны по смыслу.
Оригинальные лингвистические алгоритмы используют морфологический и синтаксический анализ, а также тезаурус русского языка для отождествления близких по смыслу слов и словосочетаний. Например, такие выражения, как "утеря нескольких библиотечных книжек" и "потеря двух библиотечных книжонок", приводятся к одному понятию "потеря библиотечной книги". Кроме того, из числа понятий исключаются общеупотребимые слова, которые не несут самостоятельной смысловой нагрузки или имеют широкое значение. Так, слова "концепция" и "развитие" сами по себе не являются понятиями, характеризующими содержание документа, но могут образовать понятие, выраженное сочетанием: "концепция развития сельского хозяйства".
Каждое понятие предлагается рассматривать в качестве имени соответствующей темы документа. Статистические данные о связях понятий в тексте и синтаксических ролях понятий во фразах позволяют оценить их вклад в общее содержание документа и, таким образом, ранжировать темы по информативности. В итоге каждой теме семантической сети присваивается так называемый тематический вес.
Максимальное значение тематического веса (равное 100) соответствует ключевой (важнейшей) теме документа. Близкое к нулю значение веса темы показывает, что она лишь вскользь упомянута в тексте, и в нем мало сведений, относящихся к данной теме.
Связи между парами тем, в свою очередь, также имеют характеристики - веса связей (от 0 до 100). Большое значение веса связи от одной темы к другой, близкое к 100, указывает на то, что подавляющая часть информации в тексте, касающаяся первой, касается в тоже время и второй темы - первая тема почти всегда излагается в контексте второй. Малое значение веса отражает тот факт, что первая тема слабо связана со второй (излагается независимо от нее). Связь между парой тем сети всегда двусторонняя, однако, связь от первой темы ко второй не всегда имеет тот же самый вес, что и обратная - от второй к первой. Такое различие в весах может указывать на то, что одна тема является подтемой другой.
Семантическая сеть представляет собой тематический индекс анализируемых текстов, который используется для поиска документов по темам и их связям, а также для расширения запроса ассоциативно связанными темами. По каждой из тем сети формируется набор предложений текста - цитат, относящихся к соответствующей теме, которые представляют тематическое резюме (реферат) текста. Кроме того, выполняется ранжирование этих предложений по весам (от 0 до 100), которые отражают их информативность для соответствующей темы и позволяют выбрать в резюме лишь наиболее информативные предложения. Общее резюме текста формируется из наиболее информативных фрагментов по ключевым темам документа.
Знание ассоциативных связей позволяет выявить скрытые зависимости между объектами-темами, интересующими аналитика - событиями, персоналиями, организациями и т.п.
При анализе текста можно воспользоваться семантической сетью, построенной на базе других текстов (эталонных), либо заданной вручную экспертом. Например, если имеется семантическая сеть, представляющая известную модель предметной области, то ее можно использовать для фильтрации информации в новостном потоке, вылавливая в тексте упоминания об известных объектах и находя подкрепления известных взаимосвязей, а также искать новые связи между заданными объектами.
Работа с семантической сетью может помочь аналитику в решении следующих задач:
- Исследование тематического состава целевой коллекции документов - например, новостного потока за выбранный интервал времени. Выявление ключевых тем и их связных скоплений (семантических полей), находящихся в фокусе внимания и влияющих на развитие ситуации. Мониторинг динамики информационного потока во времени в терминах мощности ключевых тем и их связей.
- Поиск новой, неожиданной информации, связанной с исследуемым объектом-темой. Интерес для эксперта могут представлять скрытые в документах связи с другими объектами (персонами, организациями, событиями), выявленные в семантической сети, а также ассоциативные цепочки, связывающие заданные объекты.
- Выявление в документах подкреплений известных и неизвестных связей между объектами-темами. Поиск конкретных документов, раскрывающих интересующие связи, позволяет эксперту получить детальное представление о характере отношений между объектами.
Поисковые системы.
Поисковая система это компьютерная система, предназначенная для поиска информации.
Появление поисковых систем:
Самый первый поисковый инструмент в Интернете назывался Archie. Он был создан в 1990 Аланом Эмтаджем, студентом Монреальского Университета им. Мак Гилла. Программа скачивала списки файлов, расположенные на публичных анонимных FTP сайтах, создавая базы данных имен файлов, по которым можно было производить поиск.
Archie индексировал компьютерные файлы, а Gopher — текстовые документы. Gopher был создан Марком Мак Кахиллом в Университете Миннесоты. Будучи текстовыми файлами, большинство сайтов Gopher впоследствии стали страницами Паутины.
Две другие программы, такие как Veronica и Jughead, искали файлы, сохраненные в поисковом индексе Gopher. В Veronica можно было осуществлять поиск по ключевому слову среди названий документов, перечисленных в Gopher. Jughead позволял получать информационное меню с различных серверов Gopher.
В 1993 студент МИТ Мэтью Грей изобрел первого робота, который индексировал страницы Интернет — World Wide Web Wanderer. Первоначально программа позволяла пересчитывать веб - сервера, измеряя масштабы Паутины. World Wide Web Wanderer запускали ежемесячно с 1993 по 1995 годы. Позже его использовали для получения URL при формировании первой базы данных Веба – Wandex.
Первоначально роботы создавали некое неудобство для серверов, поскольку они требовали много сетевых ресурсов, и порой серверы не выдерживали нагрузки. Новейшие роботы не снижают пропускной способности сервера и используются для построения индексов поисковых машин.
В 1993 Мартин Костер создал ALIWEB. ALIWEB позволял владельцам сайтов подавать заявки на индексацию в поисковых машинах. По мнению Костера, ALIWEB была поисковой системой, основанной на автоматизированном сборе мета-данных для Сети.
В 1993 году студенты Стэнфорда представили Excite. Программа использовала статистический анализ слов в тексте, чтобы облегчить процесс поиска. В течение одного года Excite был достаточно усовершенствован, и вышел онлайн в декабре 1995 года. На данный момент он является частью компании AskJeeves.
Сеть Galaxy возникла в 1994 году как часть поискового консорциума MCC в Университете Техаса в Остине. Galaxy была создана как алфавитный перечень, сочетающий элементы интерфейса поисковика Gopher и протокола telnet в дополнение к строке веб-поиска.
Джерри Янг и Дэвид Фило создали Yahoo в 1994 году. Проект начался с составления каталога их любимых веб-сайтов. Единственное, что отличало этот перечень от других, был комментарий к каждой ссылке URL. Через год разработчики получили финансирование и создали корпорацию Yahoo. На данный момент Yahoo втрорая востребованная поисковая система после Google.
В тот же год когда в онлайн появился Yahoo, был создана программаWebCrawler. На тот момент это была первая поисковая машина, которая индексировала весь текст веб-сайтов.
В 1994 году Lycos представил поисковую машину, предлагающую наряду с результатами поиска ссылки на темы, связанные с поисковым запросом. В 1996 году это уже была обширная поисковая система, индексирующая более 60 миллионов документов, самая крупная на тот момент. Как и многие другие поисковые системы, Lycos был разработан в университетской среде доктором Майклом Молдином в Университете Карнеги Меллона.
Поисковый сервис Infoseek был запущен в 1995 году. Он не внедрил ничего нового в систему поиска. На данный момент он принадлежит компании Уолта Диснея и работает на доменном имени Go.com
AltaVista также начала работать в 1995 году. Эта поисковая машина первой предложила расширенную систему поиска и принимала языковые запросы на так называемом «естественном языке» — например, могла обработать запрос «Как пройти в библиотеку?», вместо «библиотека». Система также предлагает возможность поиска изображений, музыки и видеофайлов.
Система Inktomy возникла в 1996 году в Университете Беркли. В июне 1999 года Inktomy ввела поиск по каталогу на основе «метода индукции». По мнению компании, «индуктивный метод принимает во внимание аналитический опыт человека и применяет его, анализируя ссылки, частоту посещений и другие параметры, чтобы определить, какие сайты наиболее посещаемы и продуктивны». В итоге Yahoo приобрело поисковую систему Inktomy в 2003 году.
Поисковая система AskJeeves была запущена в 1997 году.
Google был запущен так же в 1997 году. Он был запущен Сергеем Брином и Лари Пейджем как часть проекта Стэнфордского Университета.
В 1998 начали работу MSN-Search и Open Directory (DMOZ). База Open Directory, если верить информации на ee главной странице, «это самый большой и всеобъемлющий каталог ресурсов Сети. Его данные используют многие поисковые системы, в том числе и Google.
Современная поисковая система состоит из следующих компонентов:
Web server (веб-сервер) – сервер поисковой машины, который осуществляет взаимодействие между пользователем и остальными компонентами системы.
Spider (паук)- программа написанная по принципу браузера, предназначена для скачивания веб-страниц. Браузер предназначен для визуального использования страниц, а паук работает с HTML кодом напрямую.
Crawler («путешествующий» паук) – программа, которая автоматически уходит по всем внешним ссылкам страницы. Ее задача - поиск не известных (или измененных) документов и в расстановке приоритетов, куда дальше должен идти Spider.
Indexer (индексатор) - программа-анализатор скаченных пауками веб-страниц. Она "разбирает" на части скачанную страницу и анализирует ее элементы, такие как текст, служебные html-теги, заголовки, особенности стилистики и структурные формы
Database (база данных) – хранилище для скачанных и обработанных страниц - общая база данных поисковой машины.
Search engine results engine (система выдачи результатов) – извлекает результаты поиска из базы данных поисковой системы. Именно она решает, какие страницы более соответствуют запросу пользователя, и отсортировывает их в нужном порядке. Модуль работает согласно заданным поисковой системой алгоритмам ранжирования.
Как действует поисковая система?
Этап 1. Поиск новых страниц
Вопреки заблуждению многих, поисковые системы выдают информацию не о страницах, находящихся в интернете, а о страницах, находящихся в базе данных поисковой машины. То есть, если сайт неизвестен Яндексу или Goоgle, то и в выдаче он не появится.
Задача поисковика на этом этапе заключается в поиске всех возможных адресов страниц в интернете. Выполняет эту работу так называемый робот «паук». Интернет это ссылки, ссылки и еще раз ссылки и этот «паук» просто переходит по всевозможным ссылкам, записывая в свою базу адреса всех найденных страниц.
Задача робота создать адресный справочник по типу — Город, Улица, Дом, Квартира.
Этап 2. Индексация
Следующая программа поисковика занимается добавлением информации в базу. Она путешествует по всем известным адресам сайтов и страниц, копируя их содержимое на склады поисковой системы.
Называется этот процесс индексация – попадание информации в индекс поисковой системы.
Первый и второй процессы протекают непрерывно и, зачастую, одновременно. Постоянно пополняется база адресов страниц и база информации с этих страниц.
Кстати, в процессе индексации поисковые системы оценивают качество страниц, и информация некоторых из них не попадает в индекс. Поисковик знает об их существовании, но по каким-то причинам считает их бесполезными для пользователя, поэтому не добавляет в выдачу.
Этап 3. Определение релевантности и ранжирование
Если то, что мы обсудили в предыдущих пунктах, работает непрерывно и независимо от внешних факторов (действий человека), то третий этап в алгоритме работы поисковых систем начинает действовать только под воздействием человека.
Когда в поисковике задается запрос, система начинает искать на него ответ в наполненной базе знаний по критериям, заданным человеком в этом запросе.
Сначала, система делает выборку, определяя все релевантные запросу страницы из известных. Например, для запроса «купить холодильник Норд» релевантными будут страницы содержащие слова «купить», «холодильник», «Норд». Все страницы, содержащие одно или несколько из этих слов, попадут в выдачу поисковой системы.
Следующая задача поисковика, определить в какой последовательности пользователь увидит все эти страницы – их необходимо ранжировать. Факторов, которые будут влиять на порядок выдачи много, по словам руководителей Яндекс, их более 700. Цифра внушительная и раскрыть их все не представляется возможным. Более того, все эти факторы неизвестны ни одному сеошнику, так как поисковики держат их в тайне. Но в общих чертах эти факторы можно разделить на три группы.
1. Внутренние факторы
К этой группе относятся факторы, на которые способен повлиять сам вебмастер. В их число входит сам текст, размещенный на странице, его оформление (абзацы, заголовки и другая разметка). К ним же относятся картинки внутри текста и оформление самого сайта. Ссылки, которые размещаются внутри сайта на различные страницы (внутренняя перелинковка) также относятся к внутренним факторам.
2. Внешние факторы
В целом, эта группа факторов определяет популярность конкретного сайта по мнению других ресурсов интернета. Определяется эта популярность количеством и качеством сайтов, на которых проставлены ссылки на различные страницы вашего сайта, а также упоминания о нем в тексте. Поисковые системы оценивают эту авторитетность по сложной схеме, учитывающей очень большое количество факторов.
3. Поведенческие факторы
Поведение пользователей в интернете поисковые системы умели отслеживать не всегда. популярность эта группа факторов начала набирать сравнительно недавно. Различные счетчики статистики и специальные бары в браузерах собирают массу информации о поведении людей на сайтах. По этим данным Яндекс и Google определяют степень значимости сайтов для живых людей. Если на страницах вашего сайта надолго задерживаются посетители, внимательно читают качественные статьи, переходят по внутренним ссылкам и делают разные другие вещи, значит он людям нравится и достоин размещения на более высоких позициях поисковой выдачи.
На данный момент самые популярные поисковые системы в мире:
|
Поисковая система
|
Доля рынка в октябре 2014
|
|
Google
|
58.01 %
|
|
Baidu
|
29.06 %
|
|
Bing
|
8.01 %
|
|
Yahoo!
|
4.01 %
|
|
AOL
|
0.21 %
|
|
Excite
|
0,00 %
|
|
Ask
|
0,10 %
|
Масштаб современных поисковых систем:
Число пользователей Интернета и поисковых систем и требований пользователей к этим системам постоянно растёт. Для увеличений скорости поиска нужной информации, крупные поисковые системы содержат большое количество серверов. Сервера обычно группируют в серверные центры (дата центры). У популярных поисковых систем серверные центры разбросаны по всему миру.
В октябре 2012 года Google запустила проект «Где живёт Интернет», где пользователям предоставляется возможность познакомиться с центрами обработки данных этой компании.
О работе дата - центров поисковой системе Google известно следующее:
- Суммарная мощность всех дата - центров Googlе по состоянию на 2011 год оценивалась в 220 МВт.
- Когда в 2008 году Google планировала открыть в Орегоне новый комплекс, состоящий из трех зданий общей площадью 6,5 млн кв.м. В журнале Harper’s Magazine подсчитали, что такой большой комплекс потребляет свыше 100 МВт электроэнергии, что сравнимо с потреблением энергии города с населением 300000 человек.
- Ориентировочное число серверов Google в 2012 году — 1 000 000.
- Расходы Google на дата - центры составили в 2006 году — $1,9 млрд. , а в 2007 году — $2,4 млрд.
Размер всемирной паутины, проиндексированной Google на декабрь 2014 года, составляет примерно 4.36 миллиарда страниц.
Современные особенности поиска.
Многие поисковые системы, такие как Google и Bing, используют алгоритмы выборочного угадывания того, какую информацию пользователь хотел бы увидеть, основываясь на его прошлых действиях в системе. В результате, веб-сайты показывают только ту информацию, которая согласуется с прошлыми интересами пользователя. Этот эффект получил название «пузырь фильтров».
Всё это ведёт к тому, что пользователи получают намного меньше противоречащей своей точке зрения информации и становятся интеллектуально изолированными в своём собственном «информационном пузыре». Таким образом, «эффект пузыря» может иметь негативные последствия для формирования гражданского мнения.
Несмотря на то, что поисковые системы запрограммированы, чтобы оценивать веб-сайты на основе некоторой комбинации их популярности и релевантности, в реальности экспериментальные исследования указывают на то, что различные политические, экономические и социальные факторы оказывают влияние на поисковую выдачу.
Такая предвзятость может быть прямым результатом экономических и коммерческих процессов: компании, которые рекламируются в поисковой системе, могут стать более популярными в результатах обычного поиска в ней. Удаление результатов поиска, не соответствующих местным законам, является примером влияния политических процессов. Например, Google не будет отображать некоторые неонацистские веб - сайты во Франции и Германии, где отрицание Холокоста незаконно.
Предвзятость может также быть следствием социальных процессов, поскольку алгоритмы поисковых систем часто разрабатываются, чтобы исключить неформатные точки зрения в пользу более «популярных» результатов. Алгоритмы индексации главных поисковых систем отдают приоритет американским сайтам.
Поисковая бомба — один из примеров попытки управления результатами поиска по политическим, социальным или коммерческим причинам.
Развитие сервисов поисковых систем.
Говоря о поисковых системах, не стоит забывать о том, что у Яндекс, Google или Bing существуют собственные сервисы, призванные помочь пользователям. Помимо поисковых результатов, за годы эволюции ПС изучили поведение своих пользователей с целью повысить удовлетворенность результатами выдачи.
Собственно для этого поисковая система Яндекс и придумала механизм т.н. “Колдунщиков”, которые помогают пользователю быстро получить ответ на свой вопрос. Так, например, при вводе запроса «прогноз погоды» Яндекс прямо на странице с результатами поиска отобразит информацию о погоде на текущую дату, избавив тем самым пользователя от необходимости переходить по результатам выдачи.
Другие поисковые системы, например, Google, пошли дальше и вместо “Колдунщиков” предложили более интересное решение — “Граф знаний”.
“Граф знаний” (с англ. Knowledge Graph) — это первая ступень на пути Google к интеллектуальному поиску. Благодаря этому нововведению поисковик отображает в результатах выдачи не только стандартные ссылки, но и прямые ответы на вопросы пользователей, краткую справку об объекте запроса и информацию о связанных с ним фактах. Технически “Граф знаний” представляет собой семантическую сеть, связывающую воедино различные сущности: личности, события, сферы жизни, вещи, категории. Информационной базой для “графа знаний” служит целый ряд источников: открытая семантическая база данных Freebase, Википедия, сборник открытых данных ЦРУ и прочие источники.
Поисковые сервисы и дальше будут развиваться в сторону быстрых и актуальных ответов на вопросы пользователей, предоставляя возможность получить всю необходимую информацию прямо в SERP (выдачу) и избавляя от необходимости переходить на другие сайты.
Существует мнение, что поисковые системы своим стремлением ответить на вопрос пользователя здесь и сейчас могут уничтожить поисковую оптимизацию, став этакими глобальными базами знаний. Но такие опасения беспочвенны, поскольку для того, чтобы стать глобальными базами знаний, им нужна информация, а её хранят те самые сайты, над которыми работают те самые оптимизаторы, которые причастны к тому, что поисковые системы не стоят на месте, а постоянно эволюционируют.
Перспективы развития поисковых систем во многом можно связать с удобством поиска, в частности, с системами голосового поиска.
Системы анализа речи.
Балаболка.
Программа для чтения вслух текстовых файлов. Для воспроизведения звуков человеческого голоса могут использоваться любые речевые синтезаторы, установленные на компьютере.
Программа Balabolka предназначена для чтения вслух текстовых файлов и записи их в аудио формате. Программа может прочесть вслух содержимое буфера обмена, набираемый на клавиатуре текст или содержимое текстовых файлов DOC, PDF, HTML, RTF, CHM, DjVu, EPUB, FB2 и ODT. Управлять процессом чтения можно прямо из системного трея или при помощи сочетаний клавиш. Среди особенностей программы Balabolka можно подчеркнуть возможность настройки скорости и тембра чтения, проверку орфографии, возможность разделения текстового файла на несколько файлов меньшего размера, поиск омографов. Поддерживается возможность удаления из текста всех знаков переноса и других символов замедляющих чтение, что позволяет избежать запинок при чтении слов.
Прочтенный программой текст может быть сохранен как аудиофайл в любом из популярных форматов: MP3, MP4, WAV, OGG, WMA, M4A, M4B и AWB. Программа Balabolka также может записать текст, прочтенный компьютерным голосом, в файлы формата LRC или в ID3-теги внутри звуковых файлов формата MP3. При воспроизведении такого звукового файла в медиа-проигрывателе или современном плеере текст будет отображаться синхронно.
Программа Balabolka, также как и другие речевые синтезаторы, использует в своей работе пакеты речевых функций, разработанные корпорацией Microsoft под названием SAPI (Speech Application Programming Interface. Существуют две основные версии этого пакета: SAPI 4 и SAPI 5, программа прекрасно работает с любой из них.
Для воспроизведения звука программа Balabolka может использовать любые голоса. Голоса - отдельные программы, после установки которых, в списке голосов программы Balabolka появляются дополнительные пункты. К сожалению, изначально в программе доступен только английский голос, поэтому для чтения русского текста необходимо скачать и установить дополнительные голоса.
Рис.3. Интерфейс программы балаболка.
Горыныч
Рис. 4. Интерфейс программы горыныч.
Программа для распознавания речи, которая предназначена для управления стандартными приложениями операционной системы Windows и многими другими функциями компьютера с помощью голосовых команд. Вывод текста может производиться в любые текстовые редакторы, а также в иные программы независимо от их производителя.
Использование данной программы открыло множество явных недостатков и недоработок. Помимо нестабильного запуска программы, присутствуют ошибки интерфейса, однако основной недостаток заключается в том, что чтобы научить программу распознавать команды, необходимо приложить усилия.
Real speaker
Realspeaker показал себя как программа которая может эффективно распознавать речь. Программа обладает минималистичным интерфейсом, легко устанавливается и потребляет небольшое количество ресурсов. Данный текст набран с помощью программы realspeaker. 
Рис. 5. Интерфейс программы real speaker
Единственный минус данной программы состоит в том, что в основе её лежит алгоритм распознавания Google, который требует подключения к интернет.
Dragon naturally speaker.
Рис. 6. Интерфейс программы dragon naturally speaker
Данная программа сочетает в себе возможности голосового набора текста, а также голосового управления Windows. Программа занимает около 2Гб на диске, и может работать в оффлайн режиме. Главный её недостаток в том, что она поддерживает только английский язык.
Системы анализа текста
Textus Pro
Программа предназначена, в первую очередь, для создания материалов для сайтов. Возможности TEXTUS PRO:
Нахождение частоты и плотности использования ключевых слов, и выделение их в тексте синим цветом. Можно учитывать прямые вхождения ключевых слов или словоформы.
- Нахождение частоты и плотности использования всех слов в тексте. Если какие-то слова используются слишком часто или плотно для улучшения читабельности лучше заменить их синонимами.
- Анализ текста, указывая необходимые вам параметры: стоп-слова, числа и др.
- Редактировать текст и в зависимости от ваших целей изменить размер и шрифт текста, приглушить знаки препинания и стоп-слова.
- Подсчет количества слов и знаков (с пробелами и без пробелов) в тексте.
- А так же другие специальные возможности, для упрощения работы копирайтеров. К примеру, расчет точной стоимости работы при указании цены за 1000 знаков.
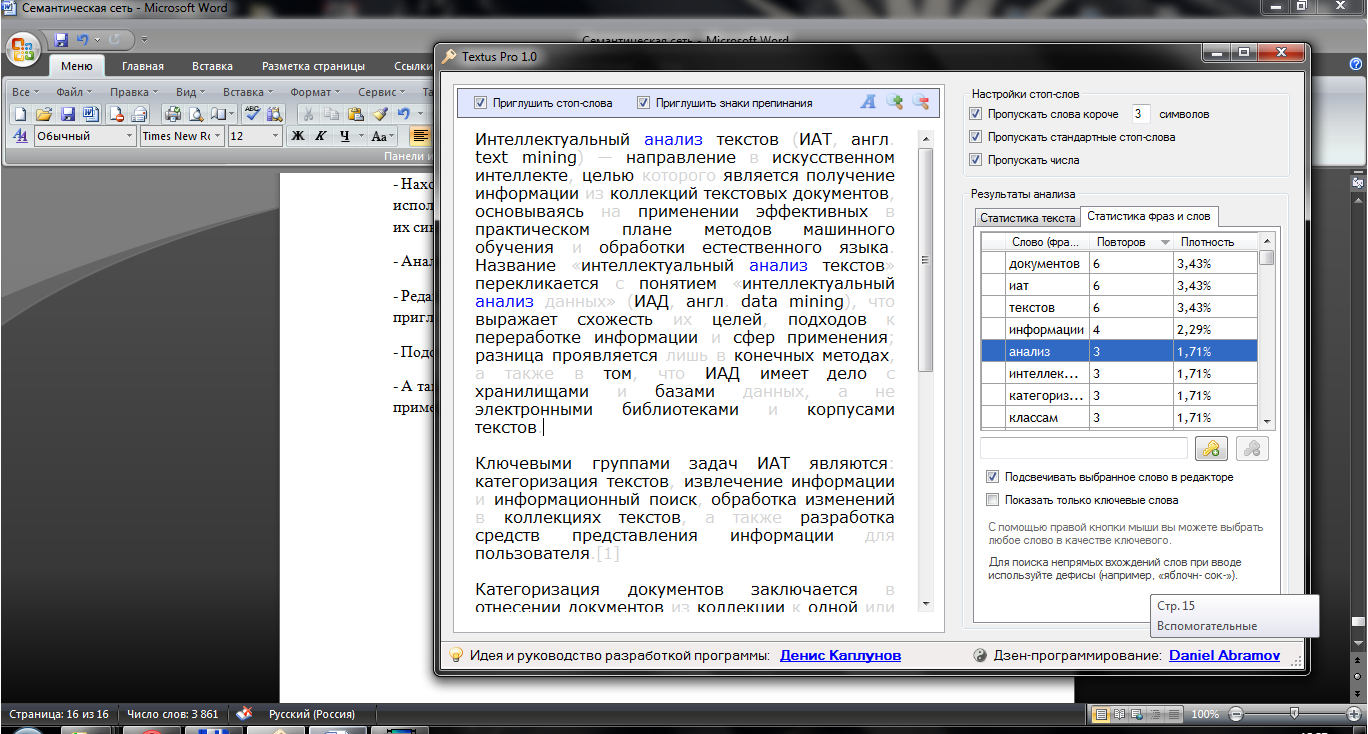
Рис.7. Интерфейс программы Textus Pro
Advego Plagiatus
Advego Plagiatus - программа поиска в интернете частичных или полных копий текстового документа с интуитивным интерфейсом. Плагиатус показывает степень уникальности текста, источники текста, процент совпадения текста. Также программа проверяет уникальность указанного URL.
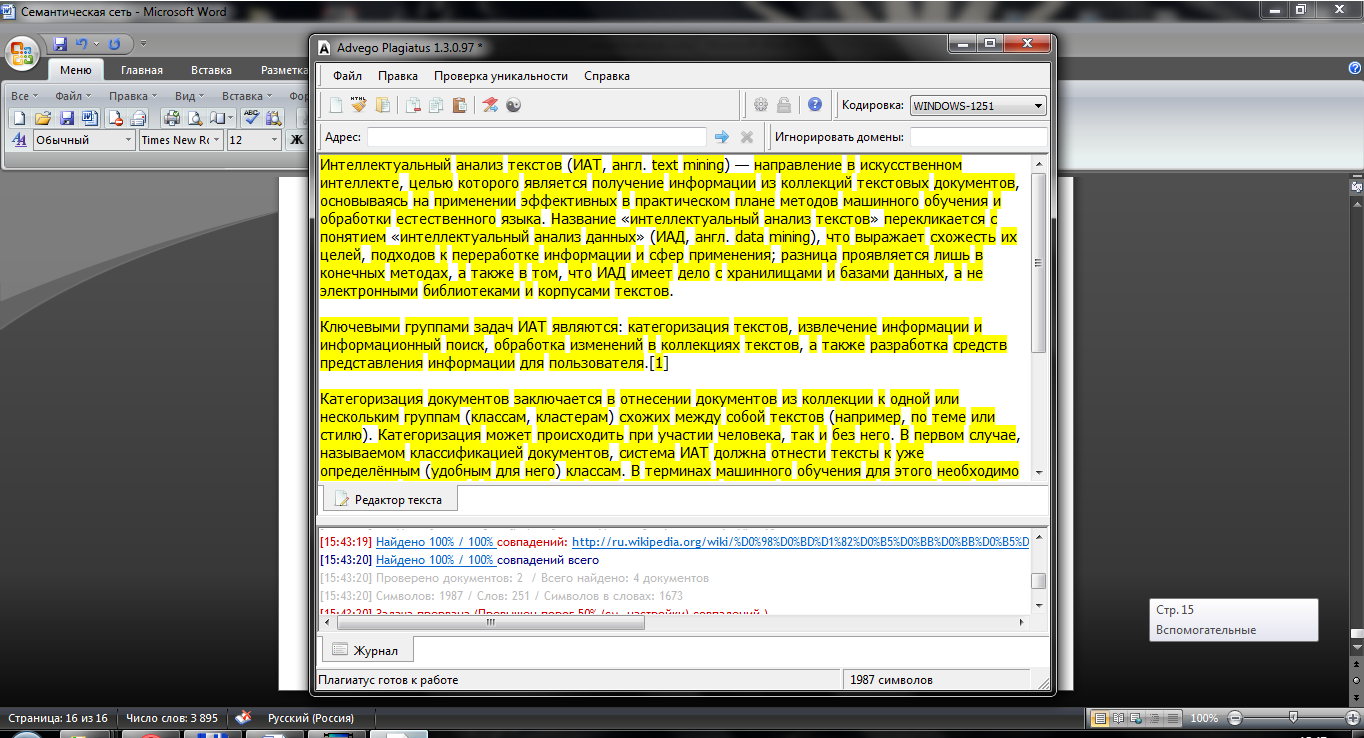
Рис.8. Интерфейс программы Advego Plagiatus
LitFrequencyMeter