Принципы работы системы управления параллельными процессами в локальных сетях компьютеров
Принципы работы системы управления параллельными процессами в локальных сетях компьютеров
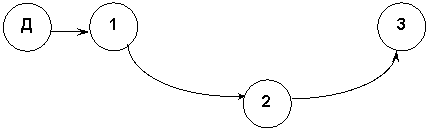
1. Умножение матриц. (гипотетический пример)
A * B =: C
Где А (m*s), B (s*n), C(m*n)
Алгоритм:
For i := 1 to s do
<Умножить вектор-строку на матрицу – A[i]*B = C[i]>
Граф зависимостей по данным (Data Flow Graph)
A[1] C[1]
A[2] C[2]
A, B C
A[k] C[k]

Д – диспетчер. Коммутирует каналы связи и распределяет строки A[i] по процессорам.
П – приёмник (вполне может быть тем же диспетчером), формирует матрицу С из полученных строк.
K – число процессоров минус 2 (или 1), которые выполняют умножение строки на матрицу.
1) Если k ³ m. Тогда каждый процессор один раз выполняет перемножение A[i]*B и передаёт результат процессору “П” . Далее процесс “П” формирует матрицу С и выдаёт результат пользователю.
2) Если k < m, то вначале просчитываются первые k строк.
Когда вычисления закончится на одной из k процессоров, то ей передаётся следующая строка – т.е. A[k+1].
И так далее, в освободившиеся процессоры передаются строки
A[k + i], i = 1 … m-k.
Достоинства данной схемы.
1) Однократеая загрузка матрицы B в процессоры-вычислители, и дальнейшая загрузка только векторов-строк A[i] (минимизация потока данных).
2) Автоматически учитывается производительность процессоров. Если процессор работает быстро, то он загружается дополнительно (случай при k < m).
2. Цели оптимизации параллельных вычислений.
1) Минимизация потока данных в DFG.
2) Учёт производительности процессоров. Включая случай зависимости её от времени (динамика).
3) Учёт скорости обмена по каналам связи между процессорами. Включая случай зависимости её от времени (динамика).
4) Коррекция DFG в реальном времени (пояняется на следующем примере итерационных методов).
далее на следующей странице…
3. Итерационные алгоритмы.
Общий случай графа потоков данных.
 циклическая связь k
циклическая связь k
процессоров
Каждый процессор (P1 Pk) или группа процессоров выполняет свою задачу (интегрирование, умножение, дифференцирование, минимизация, решение СЛУ и т.п.).
Диспетчер “Д” обеспечивает запуск итерационного процесса путём передачи исходных данных (нелевой итерации) в циклическую цепь.
Перегрузка цепи
Предположим что процессор Р1 обрабатывает поток данных быстрее по сравнению с Р2, а также обеспечивается его эффективаная загруженность (на вход Р1 быстро поступают данные). Медленная обработка данных может быть вызвана низкой скоростью передачи данных по каналу P1-P2, низкой вычислительной мощностью процессора Р2 или сложностью задачи выполняющейся на Р2.
Следовательно, в результате работы итерационного алгоритма на выходе Р1 и на входе Р2 скапливаются данные, которые ожидают дальнейшей обработки.
Далее, если Р2 работает медленнее, чем Р3 (или Р2 вообще один из самых медленных процессоров), то простаивают все P(i), i ³ 3 и Р1 (или работают с малой загруженностью).
В таком случае эффективность работы данной параллельной схемы резко снижается.
Действия.
Причиной снижения скорости вычислений является “узкое место” в цепочке процессоров, а именно медленный поцессор Р2.
Одним из способов устранения данного недостатка является динамическое изменение графа потоков данных.
Параллельно Р2 включается в работу дополнительный процессор Р2’, выполняющий ту же задачу (рабочую функцию), что и Р2.



 циклическая связь k
циклическая связь k
процессоров
Таким образом » в 2 раза повышается скорость обработки на дуге 1-2.
4. Принципы реализации.
Система реализована для ОС Windows 95 (NT), в виде исполняемой программы и дополнительной библиотеки динамической компоновки (DLL). Программа должна быть запущена на всех машинах локалной сети, участвующих в вычислениях. Дополнительная библиотека может использоваться программами, осуществляющими конкретные вычислительные и управляющие задачи.
Возможности.
1) Получение данных о системе:
· Количество процессоров (машин), участвующих в вычислениях
· Ресурсы каждого из процессоров (тип процессора, объём памяти, быстродействие)
· Пропускная способность каналов связи с каждым из процессоров (при передаче потоков данных с текущей машины)
2) Управление каналами потоков данных между процессорами (дугами):
· Создание канала между любыми двумя процессорами, как из одной из них, так и из сторонней машины
· Уничтожение, перенаправление каналов
· Получение информации о скорости обработки данных на определённой дуге (обнаружение узких мест)
· Установка желаемой скорости потока данных на дуге.
3) Запуск задач на любом из процессоров из сторонней машины.
4) Опрос состояния задачи, выполняющейся на процессоре (завершился с ошибкой, завис и т.п.)
5) Одновременная посылка данных группе процессоров посредством использования возможностей широковещания в локальных сетях, т.е. сразу по нескольким каналам связи.
Реализация.