Избыточные коды
Страница 3
где m(х)- частное, а с(х)- остаток. Так как операции суммирования и вычитания по модулю 2 совпадают, то выражение (7.12) перепишем в виде: (7.13)
Из (7.13) следует, что многочлен делится на р(х) и, следовательно, является искомым.
Многочлен имеет следующую структуру: первые n-k членов низшего порядка равны нулю, а коэффициенты остальных совпадают с соответствующими коэффициентами информационного многочлена а(х). Многочлен с(х) имеет степень меньше n-k. Таким образом, в найденном многочлене b(x) коэффициенты при х в степени n-k и выше совпадают с информационными символами, а коэффициенты при остальных членах, определяемых многочленом с(х), совпадают с проверочными символами. На основе приведенных схем умножения и деления многочленов и строятся кодирующие устройства для циклических кодов.
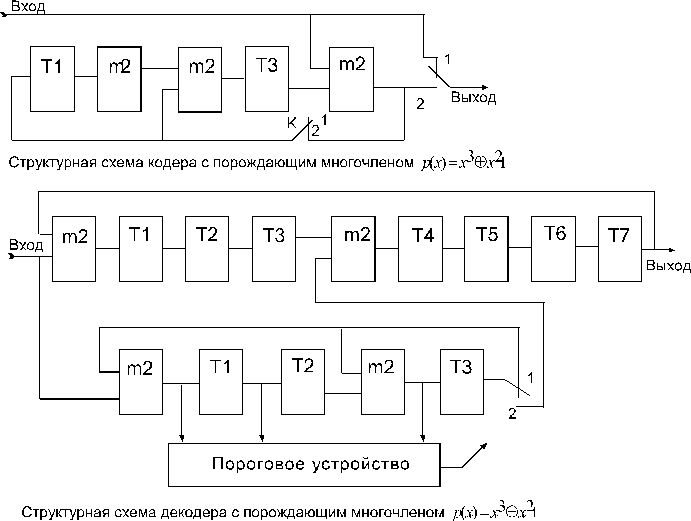
В качестве примера приведена схема кодера и декодера для кода (см. рис.) с порождающим многочленом:
Код имеет кодовое расстояние d=3, что позволяет ему исправлять все однократные ошибки.
Принятая кодовая комбинация одновременно поступает в буферный регистр сдвига, служащий для запоминания кодовой комбинации и для ее циклического сдвига, и на устройство деления на многочлен р(х) для вычисления синдрома. В исходном состоянии ключ находится в положении 1. После семи тактов буферный регистр оказывается загруженным, а в регистре устройства деления будет вычислен синдром. Если вес синдрома больше единицы, то декодер начинает производить циклические сдвиги комбинации в буферном регистре при отсутствии новой комбинации на входе и одновременно вычислять их синдромы s(x)ximodp(x) в устройстве деления. Если на некотором 1-м шаге вес синдрома окажется меньше 2, то ключ переходит в положение 2, обратные связи в регистре деления разрываются. При последующих тактах ошибки исправляются путем подачи содержимого регистра деления на вход сумматора по модулю 2, включенного в буферный регистр. После семи тактов работы декодера в автономном режиме исправленная комбинация в буферном регистре возвращается в исходное положение (информационные символы будут занимать старшие разряды).
Существуют и другие, более универсальные, алгоритмы декодирования.
К циклическим кодам относятся коды Хэмминга, которые являются примерами немногих известных совершенных кодов. Они имеют кодовое расстояние d=3 и исправляют все одиночные ошибки. Среди циклических кодов широкое применение нашли коды Боуза- Чоудхури- Хоквингема (БЧХ).
Сверточные коды
Методы описания сверточных кодов.
Кодер СК содержит регистр памяти для хранения определенного числа информационных символов и преобразователь информационной последовательности в кодовую последовательность. Процесс кодирования производится непрерывно. Скорость кода R=k/n, где k - число информационных символов, одновременно поступающих на вход кодера, n - число соответствующих им символов на выходе кодера. Схема простого кодера показана на рис. 1.1а.
Информационные двоичные символы u поступают на вход регистра с К разрядами. На выходах сумматоров по модулю 2 образуются кодовые символы a(1) и a(2). Входы сумматоров соединены с определенными разрядами регистра. За время одного информационного символа на выходе образуются два кодовых символа (R= 1/2). Возможно кодирование и с другими скоростями. При скорости 2/3 на вход кодера одновременно поступает k=2 информационных символа, на выходе при этом образуется n=3 кодовых символа. Схема такого кодера показана на рис. 1.1,6.
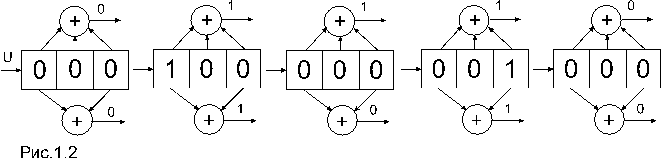
Рассматриваемый код называется сверточным, постольку последовательность кодовых символов а может быть определена как свертка информационных символов u с импульсным откликом кодера. На рис. 1.2 показано прохождение единичной последовательности u=100… через кодер.
Символы a(1) и a(2) на его выходе образуют импульсный отклик h= 00111011 00 . Таким образом, если на входе кодера действует произвольная информационная последовательность и, то последовательность на его выходе есть сумма по модулю 2 всех импульсных откликов, обусловленных действием смещенных во времени символов 1. Сверточный кодер, как автомат с конечным числом состояний, может быть описан диаграммой состояний. Диаграмма представляет собой направленный граф и описывает все возможные переходы кодера из одного состояния в другое, а также содержит символы выходов кодера, которые сопровождают эти переходы.
|
|  |
Первоначально кодер находится в состоянии 00, и поступление на его вход информационного символа u=0 перевозят его также в состояние 00. При этом на выходе кодера будут символы a(1)a(2)=00. На диаграмме этот переход обозначается петлей 00, выходящей из состояния 00 и вновь возвращающейся в это состояние. Далее, при поступлении символа u=1 кодер переходит в состояние 10, при этом, на выходе будут символы a(1)a(2)=11. Этот переход из состояния 00 в состояние 10 обозначается пунктирной линией. Далее возможно поступление на вход кодера информационных символов 0 либо 1. При этом кодер переходит в состояние 01 либо 11, а символы на выходе будут 10 либо 01 соответственно. Процесс построения диаграммы заканчивается когда будут просмотрены все возможные переходы из одного состояния во все остальные.
Решетчатая диаграмма является разверткой диаграммы состояний во времени. На решетке состояния показаны узлами, а переходы соединяющими их линиями. После каждого перехода из одного состояния в другое происходит смещение на один шаг вправо. Решетчатая диаграмма дает наглядное представление всех разрешенных путей, по которым может продвигаться кодер при кодировании. Каждой информационной последовательности на входе кодера соответствует единственный путь по решетке. Построение решетки производится на основе диаграммы состояний. Исходное состояние S(1)S(2)=0. С поступлением очередного символа u=0 либо 1 возможны переходы в состояния 00 либо 10, обозначаемые ветвями 00 и 11. Процесс следует продолжить, причем через три шага очередной фрагмент, решетки будет повторяться. Пунктиром показан путь 11100001 ., соответствующий поступлению на вход кодера информационной последовательности 1011 .
|
| 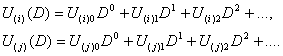 |
Для описания кодера последовательности символов на его входе и выходе представляют с использованием оператора задержки:
Здесь индексы в скобках обозначают: i- номер входа кодера, 1≤ j≤ n, j- номер выхода кодера, 1≤i≤ k. Индексы без скобок (0, 1, 2, .) обозначают дискретные моменты времени.
Процесс кодирования может быть представлен как умножение многочлена входной информационной последовательности u(D) на порождающие многочлены кода G(j)(D), которые описывают связи ячеек регистра кодера с его выходами (1.1):