Кластерный анализ в портфельном инвестировании
Страница 2
Разбиение множества ценных бумаг на отдельные кластеры в зависимости от динамики доходности осуществляется следующим образом: данные по доходности ценных бумаг на протяжении базы прогноза компонуются в общую матрицу вида:
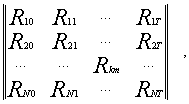 (1)
(1)
где Rkm – доходность по k-й ценной бумаге за m-й период,
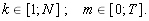
Далее, разбиение на кластеры происходит через вычисление евклидова расстояния между ценными бумагами p и q по формуле
 (2)
(2)
где m – номер периода,
sRm – среднеквадратическое отклонение доходности за период m.
Критическая величина разбиения предполагается равной квадратному корню из количества периодов T, то есть средней величине евклидового расстояния:
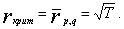 (3)
(3)
Преимущество данной методики заключается, во-первых, в том, что она позволяет с крайне высокой степенью точности группировать ценные бумаги со сходными тенденциями в изменении доходности на протяжении всего периода, определяющего базу прогноза, что дает основания рассчитывать на сохранение подобной тенденции и в дальнейшем.
Вторым ее преимуществом является возможность полной автоматизации, что значительно облегчает работу, позволяя использовать современные вычислительные средства, а также обрабатывать однородную информацию, получаемую из электронных баз данных. Поэтому она может быть без особых затруднений внедрена не только в компьютерных системах отдельных фирм, занимающихся инвестированием, но также и на соответствующих ресурсах сети Интернет.
Пожалуй, наиболее острой проблемой, возникающей перед специалистами по факторному анализу, является подбор четких и ясных критериев, позволяющих отсеять малозначимые факторы, повышающие размерность модели без увеличения ее точности, и при этом правильно определить вес для остальных факторов. Доказательством важности этого вопроса, а также отсутствия однозначно оптимальных решений, является изобилие всевозможных критериев отбора значимых компонент. Достаточно назвать такие известные методы, как расчет варимакс-критерия, n-критерий, отбор при помощи t-критерия Стьюдента и т.п.
Очевидно, что вводить в модель очередной фактор целесообразно только в том случае, если он в достаточной степени понижает уровень энтропии, а следовательно, увеличивает значение R-квадрат. Каким образом численно выразить прирост данной величины в зависимости от количества вводимых факторов? Рассмотрим эту проблему в свете коэффициентов последовательной детерминации.
Пусть имеются N факторов X1 .XN, предположительно влияющих на доходность инвестиционного портфеля. При вводе в уравнение регрессии фактора Xi показатель R-квадрат принимает некоторое определенное значение. Выберем фактор, при котором оно будет наибольшим:
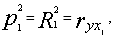 (4)
(4)
где P12 - коэффициент последовательной детерминации для данного фактора,
ryx1 - парный коэффициент корреляции между доходностью и этим фактором.
Теперь вводится в полученное уравнение регрессии второй фактор таким образом, чтобы значение R-квадрат снова оказалось максимально возможным, и затем рассчитываем второй коэффициент последовательной детерминации:
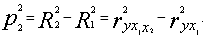 (5)
(5)
Аналогичным образом рассчитываем следующие коэффициенты:
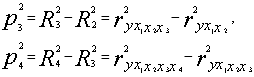 и т.д.
и т.д.
Базовый отбор факторов продолжается до тех пор, пока величина получаемых коэффициентов последовательной детерминации не станет меньше некоторого критического значения. Учитывая, что в механизм расчета скорректированной величины R-квадрат входит поправка на возрастание энтропии при вводе новых факторов, ее прирост на каждой итерации алгоритма должен быть положительным и, следовательно, критическое значение p должно быть больше нуля.
Данный метод позволяет отобрать из всех имеющихся факторов именно те, которые оказывают наибольшее влияние на доходность рассматриваемых ценных бумаг. Это позволяет существенно понизить размерность модели, создаваемой на основе методики, ускорить вычисления и при этом отбросить данные, не имеющие большого влияния на интересующие нас показатели. Как правило, от выявленных главных компонент зависит не менее 85% общей дисперсии, что лишний раз показывает эффективность выбранного метода анализа.
Теперь, когда определены методы отбора факторов и технология разбиения множества ценных бумаг на отдельные кластеры, можно приступать непосредственно к построению методики оптимизации инвестиционного портфеля. Учитывая, что в настоящее время внедрение любой экономической методики немыслимо без автоматизации, существует алгоритм, по которому надлежит производить операции для получения искомого результата: оптимизированного набора ценных бумаг, позволяющих получить максимальную прибыль при заданном уровне риска.
На первом этапе определяются исходные массивы данных, которые подлежат математической обработке.
В начале имеются следующими исходными данными: S1, S2, ., SN – рассматриваемое множество ценных бумаг;
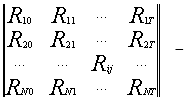 (6)
(6)
матрица доходности ценных бумаг S1-SN за периоды [0 ; T],
где Rij – доходность по ценной бумаге i за j-й период;
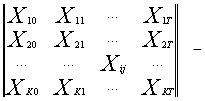 (7)
(7)
матрица факторов X1-XK за периоды [0 ; T],
где Xij – значение фактора Xi за j-й период;
sп – оценка риска предполагаемого портфеля ценных бумаг.
Теперь необходимо определить доли m1, ., mN имеющихся в инвестиционном портфеле ценных бумаг с целью максимизации доходности в следующем периоде при заданном уровне риска:
 (8)
(8)
где уровень доходности Ri вычисляется как отношение ожидаемой в отчетный период стоимости ценной бумаги Si к курсовой стоимости в момент формирования портфеля за вычетом единицы.
Так, доходность за месяц в момент времени t=1 вычисляется следующим образом:
 (9)
(9)
В случае, когда инвестор не имеет возможностей продавать ценные бумаги без покрытия, вводится дополнительное условие: my>0 , где y – номер соответствующей ценной бумаги.
3. Алгоритм оптимизации портфеля с применением кластерного анализа
Предлагаемый алгоритм можно условно разбить на четыре основные стадии:
1) Разбиение множества ценных бумаг на отдельные кластеры;
2) Определение факторов, влияющих на доходность составляющих каждого кластера. Расчет факторных весов. Построение уравнения регрессии;
3) Прогнозирование динамики выбранных факторов;
4) Вычисление ожидаемой доходности и степени риска для каждой ценной бумаги;
5) Определение оптимального набора ценных бумаг и их долевого веса в инвестиционном портфеле для обеспечения максимизации доходности.
Теперь можно рассмотреть эти стадии подробнее:
1. Разбиение множества ценных бумаг на отдельные кластеры.
Эта стадия начинается с формирования таблицы эвклидовых расстояний между имеющимися ценными бумагами:
Таблица 1 – Таблица эвклидовых расстояний
|
Ценные бумаги: |
S1 |
S2 |
…Sj… |
SN |
|
S1 |
- |
r1,2 |
r1,j |
r1,N |
|
S2 |
|
- |
r2,j |
r2,N |
|
…Si… |
|
|
ri,j |
ri,N |
|
SN |
|
|
|
- |