Моделирование промышленной динамики в условиях переходной экономики
Страница 3
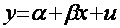 (1.2)
(1.2)
Величина у, рассматриваемая как зависимая переменная, состоит из двух составляющих: 1) неслучайной составляющей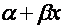 , где х выступает как объясняющая (или независимая) переменная, а постоянные величины
, где х выступает как объясняющая (или независимая) переменная, а постоянные величины 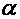 и
и 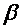 - как параметры уравнения; 2) случайного члена u.
- как параметры уравнения; 2) случайного члена u.
На рис. 1.1 показано, как комбинация этих двух составляющих определяет величину у. Показатели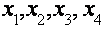 – это четыре гипотетических значения объясняющей переменной. Если бы соотношение между у и х было точным, то соответствующие значения у были бы представлены точками
– это четыре гипотетических значения объясняющей переменной. Если бы соотношение между у и х было точным, то соответствующие значения у были бы представлены точками  на Q1, Q2, Q3, Q4 прямой. Наличие случайного члена приводит к тому, что в действительности значение у получается другим. Предполагалось, что случайный член возмущения положителен в первом и четвертом наблюдениях и отрицателен в двух других. Поэтому если отметить на графике реальные значения у при соответствующих значениях х, то мы получим точки Р1, Р2, Р3, Р4.
на Q1, Q2, Q3, Q4 прямой. Наличие случайного члена приводит к тому, что в действительности значение у получается другим. Предполагалось, что случайный член возмущения положителен в первом и четвертом наблюдениях и отрицателен в двух других. Поэтому если отметить на графике реальные значения у при соответствующих значениях х, то мы получим точки Р1, Р2, Р3, Р4.
Следует подчеркнуть, что точки Р – это единственные точки, отражающие реальные значения переменных на рис. 1.1. Фактические значения и и, следовательно, положение точек Q неизвестны, так же как и фактические значения случайного члена. Задача регрессионного анализа состоит в получение оценок и и, следовательно, в определении положения прямой по точкам Р.
Очевидно, что чем меньше значения и, тем легче эта задача. Действительно, если бы случайный член отсутствовал вовсе, то точки Р совпали бы с точками Q и точно бы показали положение прямой. В этом случае достаточно просто построить эту прямую и определить значения и.
Рис. 1.1. Истинная зависимость между у и х
Почему же существует случайный член? Имеется несколько причин.
1. Невключение объясняющих перемен. Соотношение между у и х почти наверняка является очень большим упрощением. В действительности существуют другие факторы, влияющие на у, которые не учтены в формуле (1.2). Влияние этих факторов приводит к тому, что наблюдаемые точки лежат вне прямой. Часто происходит так, что имеются переменные, которые мы хотели бы включить в регрессионное уравнение, но не можем этого сделать потому, что не знаем, как их измерить, например психологические факторы. Возможно, что существуют так же другие факторы, которые мы можем измерить, но которые оказывают слабое влияние, что их не стоит учитывать. Кроме того, могут быть факторы, которые являются существенными, но которые мы из-за отсутствия опыта не считаем. Объединив все эти составляющие, мы получаем то, что обозначено, как и. Если бы мы точно знали, какие переменные присутствуют здесь, и имели возможность, точно их измерить, то могли бы включить их в уравнение и исключить соответствующий элемент из случайного члена. Проблема состоит в том, что мы никогда не можем быть уверены, что входит в данную совокупность, а что – нет.
2. Агрегирование переменных. Во многих случаях рассматриваемая зависимость – это попытка объединить вместе некоторое число микроэкономических соотношений. Например, функция суммарного потребления – это попытка общего выражения совокупности решений отдельных индивидах о расходах. Так как отдельные соотношения, вероятно, имеют разные параметры, любая попытка определить соотношение между совокупности расходами и доходом является лишь аппроксимацией. Наблюдаемое расхождение при этом приписывается наличию случайного члена.
3. Неправильное описание структуры модели. Структура модели может быть описана неправильно или не вполне правильно. Здесь можно провести один из многих возможных примеров. Если зависимость относится к данным о временном ряде, то значение у может зависеть не от фактического значения х, а от значения, которое ожидалось в предыдущем периоде. Если ожидаемое и фактическое значения тесно связаны, то будет казаться, что между у и х существует зависимость, но это будет лишь аппроксимация, и расхождение вновь будет связано с наличием случайного члена.
4. Неправильная функциональная спецификация. Функциональное соотношение между у и х математически может быть определено неправильно. Например, истинная зависимость может не являться линейной, а быть более сложной. Безусловно, надо избежать возникновения этой проблемы, использую подходящую математическую формулу, но любая самая изощренная формула является лишь приближением, и существующее расхождение вносит вклад в остаточный член.
5. Ошибка измерения. Если в измерении одной или более взаимосвязанных переменных имеются ошибки, то наблюдаемые значения не будут соответствовать точному соотношению, и существующее расхождение будет вносить вклад в остаточный член.
Остаточный член является суммарным проявлением всех этих факторов. Очевидно, что если бы нас интересовало только измерение влияние х на у, то было бы значительно удобнее, если бы остаточного члена не было. Если бы он отсутствовал, мы бы знали, что любое изменение у от наблюдения к наблюдению вызвано изменением х, и смогли бы точно вычислить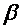 . Однако в действительности каждое изменение у отчасти вызвано изменением и, и это значительно усложняет жизнь. По этой причине и иногда описывается как шум.
. Однако в действительности каждое изменение у отчасти вызвано изменением и, и это значительно усложняет жизнь. По этой причине и иногда описывается как шум.
Интерпретация уравнения регрессии.
Существуют два типа интерпретации уравнения регрессии. Первый этап состоит в словесном истолковании уравнения так, чтобы это было понятно человеку, не являющемуся специалистом в этой области статистики. На втором этапе необходимо решить, следует ли ограничиться этим или провести более длительное исследование зависимости.
В рассматриваемом случае экстраполяция к вертикальной оси приводит к выводу о том, что если доход был бы равен нулю, то расходы на питание составили бы 55.3 млрд. долл. такое толкование может быть правдоподобным в отношении отдельного человека, так как он может израсходовать на питание Оба этапа чрезвычайно важны. Второй этап мы рассмотрим несколько позже, а пока обратим основное внимание на первый этап. Это будет проиллюстрировано моделью регрессии для функции спроса, т.е. регрессией между расходами потребителя на питание (у) и располагаемым личным доходом (х) по данным, приведенным в таблице для США за период с 1959 по 1983 г. Данные представлены в виде графика.
Предположим, что истинная модель описывается следующим выражением:
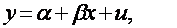 (1.3)
(1.3)
и оценена регрессия
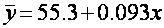 (1.4)
(1.4)
Полученный результат можно истолковать следующим образом. Коэффициент при х (коэффициент наклона) показывает, что если х увеличивается в на одну единицу, то у возрастает на 0.093 единицы. Как х, так и у измеряются в миллиардах долларов в постоянных ценах; таким образом, коэффициент наклона показывает, что если доход увеличивается на 1 млрд. долл., то расходы на питание возрастают на 93 млн. долл. Другими словами, из каждого дополнительного доллара дохода 9.3 цента будут израсходованы на питание.