Анализ финансовых результатов на примере магазина «Кош»
Страница 17
Коэффициент множественной корреляции, который принимает значение от 0 до 1, более универсальный: чем ближе его значение к 1, тем в большей степени учтены факторы, влияющие на зависимую переменную, тем более точной может быть модель.
Свойство 2. Коэффициент корреляции не зависит от выбора начала отсчета и единицы измерения, то есть
р (a1X + b a2 Y + b) = r xy , ( 19 )
где a1, a2 , b - постоянные величины, причем a1 > 0 , a2 > 0.
Случайные величины X,Y можно уменьшать (увеличивать) в a раз, а также вычитать или прибавлять к значениям X и Y одно и тоже число b - это не приведет к изменению коэффициента корреляции r.
Свойство 3. При r = +-1 корреляционная связь представляется линейной функциональной зависимостью. При этом линии регрессии y по x и x по y совпадают.
Свойство 4. При r = 0 линейная корреляционная связь отсутствует и параллельны осям координат.
Рассмотренные показатели во многих случаях не дают однозначного ответа на вопрос о наборе факторов. Поэтому в практической работе с использованием ПЭВМ чаще осуществляется отбор факторов непосредственно в ходе построения модели методом пошаговой регрессии. Суть метода состоит в последовательном включении факторов. На первом шаге строится однофакторная модель с фактором , имеющим максимальный коэффициент парной корреляции с результативным признаком. Для каждой переменной регрессии , за исключением тех, которые уже включены в модель , рассчитывается величина С(j) , равная относительному уменьшению суммы квадратов зависимой переменной при включении фактора в модель. Эта величина интерпретируется как доля оставшейся дисперсии независимой переменной, которую объясняет переменная j. Пусть на очередном шаге k номер переменной, имеющей максимальное значение, соответствует j. Если Сk меньше заранее заданной константы, характеризующей уровень отбора, то построение модели прекращается. В противном случае k-я переменная вводится в модель.
После того, как с помощью корреляционного анализа выявлены статистические значимые связи между переменными и оценена степень их тесноты, переходят к математическому описанию
Регрессионной моделью системы взаимосвязанных признаков является такое уравнение регрессии, которое включает основные факторы, влияющие на вариацию результативного признака, обладает высоким (не ниже 0,5) коэффициентом детерминации и коэффициентом регрессии, интерпретируемыми в соответствии с теоретическим знанием о природе связей в изучаемой системе.
Основной задачей линейного регрессионного анализа является установление формы связи между переменными, а так же выбор наиболее информативных аргументов Xj; оценивание неизвестных значений параметров aj уравнения связи и анализ его точности.
В регрессионном анализе вид уравнения выбирается исходя из физической сущности изучаемого явления и результатов наблюдений. Простейший случай регрессионного анализа для линейной зависимости между зависимой переменной Y и независимой переменной Х выражается следующей зависимостью:
Y = a0 + a1X + e , ( 20 )
где a0 – постоянная величина (или свободный член уравнения).
a1 – коэффициент регрессии, определяющий наклон линии, вдоль которой рассеяны данные наблюдений. Это показатель, характеризующий процентное изменение переменой Y, при изменении значения X на единицу. Если a1 > 0 –переменные X и Y положительно коррелированны, если a2 < 0 – отрицательно коррелированны;
e - независимая ((М (ei ej ) = 0, при i ¹ j ) нормально распределенная случайная величина – остаток (помеха) с нулевым математическим ожиданием (me = 0) и постоянной дисперсией ( De = s2 ). Она отражает тот факт, что изменение Y будет недостаточно описываться изменением X – присутствуют другие факторы, неучтенные в данной модели.
Параметры модели оцениваются по методу наименьших квадратов, который дает наилучшие (эффективные) линейные несмещенные оценки.
Если записать выражение для определения коэффициентов регрессии в матричной форме, то становится очевидным, что решение задачи возможно лишь тогда, когда столбцы и строки матрицы исходных данных линейно независимы. Для экономических показателей это условие выполняется не всегда. Линейная или близкая к ней связь между факторами называется коллиниарностью и приводит к линейной зависимости нормальных уравнений, что делает вычисление параметров либо невозможным, либо затрудняет содержательную интерпретацию параметров модели. Чтобы избавиться от коллиниарности, в модель включают лишь один из линейно связанных между собой факторов, причем тот, который в большей степени связан с зависимой переменной.
Проверка качества модели
Качество модели оценивается стандартным для математических моделей образом: по адекватности и точности. Расчетные значения получаются путем подстановки в модель фактических значений всех включенных факторов.
Кроме рассмотренных выше характеристик, целесообразно использовать корреляционное отношение (индекс корреляции), а также характеристики существенности модели в целом и ее коэффициентов.

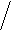 В качестве характеристики тесноты связи применяется индекс корреляции (Iyx ) переменных Y по X.
В качестве характеристики тесноты связи применяется индекс корреляции (Iyx ) переменных Y по X.
 Iyx = 1- (se2 / sy2) , ( 21 )
Iyx = 1- (se2 / sy2) , ( 21 )
где se2 – это дисперсия параметра Х относительно функции регрессии, то есть остаточная дисперсия, которая характеризует влияние на Y прочих неучтенных факторов в модели;
sy2 – полная дисперсия, она измеряет влияние параметра X и Y.
Из этого следует, что 0 £ Iyx £ 1. При этом Iyx = 0 означает полное отсутствие корреляционной связи между зависимой переменной Y и объясняющей переменной Х. В то же время максимальное значение индекса корреляции (Iyx = 1) соответствует наличию чисто функциональной связи между переменными X и Y и, следовательно, возможность детерминированного восстановления значений зависимой переменной Y по соответствующим значениям объясняющей переменной X.
Данный коэффициент является универсальным, так как он отражает тесноту связи и точность модели, а также может использоваться при любой форме связи переменных. При построении однофакторной модели и их линейной зависимости он равен коэффициенту линейной корреляции.
Коэффициент множественной корреляции (индекс корреляции), возведенный в квадрат, называется коэффициентом детерминации. Он показывает долю вариации результативного признака, находящегося под воздействием изучаемых факторов, то есть определяет, какая доля вариации признака Y учтена в модели и обусловлена влиянием на него факторов.
В качестве меры точности применяют несмещенную оценку дисперсии остаточной компоненты , которая определяется по формуле:
n _
S = S2 / å (xi – x) , ( 22 )
i=1
где S2 – дисперсия зависимой переменной Y.
n _ n
S2 = å (yi – yi)2 / n-2 = å ei2 / n-2 ( 23 )
i=1 i=1
Квадратный корень из этой величины (S) называется стандартной ошибкой оценки:
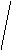
 n _
n _
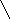 S а1= S2 / å (xi – x) , ( 24 )
S а1= S2 / å (xi – x) , ( 24 )
i=1
Коэффициент а1 есть мера наклона линии регрессии. Очевидно, чем больше разброс значений Y вокруг линии регрессии, тем больше в среднем ошибка в определении ее наклона. Кроме того, чем больше число наблюдений n, тем больше сумма å (xi – x)2 и тем, самым меньше стандартная ошибка оценки а1 .
Проверка значимости модели регрессии осуществляется по F-критерию (критерий Фишера), расчетное значение которого определяется по формуле:
Fp = {Q1 * (n - m)} / {Q2 * (m-1)}, ( 25 )
где m – число объясняющих (независимых переменных);
n – число наблюдений;
Q1 - сумма квадратов, объясняемая регрессией, то есть сумма квадратов отклонений обусловленных влиянием признака Х;