ПСИХОЛИНГВИСТИЧЕСКОЕ ИССЛЕДОВАНИЕ ПРОЦЕССОВ ИДЕНТИФИКАЦИИ СЛОВА
Страница 8
Как одна из возможностей рассматривается подход к звуковому коду как “слуховому образу” [Baddeley & Lewis 1981]. В работе [McCutchen et al. 1991] высказывается предположение, что звуковой код является “фонетически специфичным” и включает, по крайней мере, согласные, стоящие в начале слова, и некоторую артикуляторную информацию, т.е. фонологическая репрезентация может приближаться к произношению слова. Другое предположение о природе фонологической репрезентации основывается на идее поэтапного реконструирования, при этом сначала “собираются” согласные, а затем гласные [Berent & Perteffi 1995]. Допускается также трактовка звукового кода как абстрактного понятия, содержащего достаточную информацию, чтобы человек мог различать слова в речи. Существуют данные, что в экспериментальных ситуациях характер фонетической или фонологической репрезентации и степень ее участия в процессе идентификации слова изменяется в зависимости от задания и контекста [Davelaar et al. 1978; Hawkins et al. 1976]. Предполагается, что при идентификации изолированного слова релевантная репрезентация (звуковой код), вероятно, более абстрактна, чем при процессах обработки некоторого контекста. Малоизученным остается вопрос о взаимодействии фонетических или фонологических репрезентаций и морфологической информации о слове.
К настоящему моменту накоплен большой экспериментальный материал, показывающий, что при выполнении разнообразных заданий с написанным словом фонологическая репрезентация активируется практически сразу после визуального предъявления графического стимула. В частности, Л.А. Петеффи и его коллеги [Perteffi & Bell 1991; Perteffi, Bell & Delaney 1988; Perteffi, Zhang & Berent 1992] установили, что при идентификации визуального стимула активация фонологической репрезентации осуществляется в пределах 60 мсек после его предъявления.
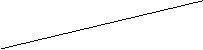
Прилагательные нашего экспериментального списка, представившие наибольшую трудность для идентификации, хорошо иллюстрируют гипотезу В.Д. Марслена-Вильсона, который полагает, что слова в ментальном лексиконе упорядочены по их начальным сегментам [Marslen-Wilson 1980]. Согласно его “когортной модели”, доступ к слову осуществляется путем последовательного перебора списка слов, организованного по их начальным фонемам. Согласно этой модели, распознавание слова осуществляется следующим образом: одна или две первые фонемы активируют в памяти человека все слова, начинающиеся с этой последовательности фонем. Сужение когорты слов - кандидатов на распознавание происходит за счет сопоставления членов когорты с поступающей сенсорной информацией. Процесс сужения имеет место до тех пор, пока из всех возможных кандидатов остается одно слово, соответствующее сенсорному сигналу. Возможный путь идентификации слова ТОЛМАЧЕСКИЙ представлен на рис.1.
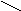
 толмаческий толмаческий
толмаческий толмаческий

 толкач толкач толмаческий
толкач толкач толмаческий
тупой
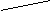
 толочь толочь толмач толмаческий
толочь толочь толмач толмаческий
 толмач толмач
толмач толмач

 толмачев толмачев толмачев
толмачев толмачев толмачев
 толкачевский толкаческий
толкачевский толкаческий
Рис.1
При встрече с началом слова Т . в памяти человека всплывает огромный ряд слов, образующих начальную когорту: “тупой”, “толочь”, “толмач” и т.д., которая затем сужается под влиянием последующих элементов слова до тех пор, пока не остается одно слово. Можно предполагать, что реакция ии. представляет собой актуализацию какого-то слова в процессе перебора возможных кандидатов на этапе доступа, которое по некоторым причинам субъективно переживается как наиболее близкое стимулу.
Как отмечают К. Эммори и В. Фромкин [Emmory & Fromkin 1988], многочисленные свидетельства в пользу когортной модели подтверждают тот факт, что начальные элементы слова действительно обеспечивают быстрый доступ к нему. Но это не означает, что невозможно существование других оснований для упорядочивания слов в ментальном лексиконе. Авторы когортной модели полагают, что конечные элементы слова не всегда необходимы для распознавания, из чего можно сделать вывод, что они являются менее значимыми. Однако существует и другая точка зрения, сторонники которой считают, что для распознавания слова конечные элементы важны даже более, чем те, которые находятся в середине слова (см., например, [Cutler, Hamkins & Gilligan 1985. Цит. по: Emmory & Fromkin 1988]). Тем самым признается возможность упорядочивания единиц ментального лексикона по конечной рифмуемой структуре или конечному слогу.
Когортная модель была предложена авторами как попытка воссоздать процесс распознавания звукового сигнала. Обсуждая наши экспериментальные данные с позиций этой модели, мы изначально предполагаем возможность функционирования подобных процессов при идентификации визуально предъявленного стимула, что возможно при осуществлении ряда преобразований с учетом применения правил графемно-фонемной конверсии. Однако, как показывает наш экспериментальный материал, распознавание стимула может происходить путем опоры на графическую форму слова. Наличие в ментальном лексиконе орфографической репрезентации слова обеспечивает возможность восприятия визуально предъявленных слов, осознание которых не может быть обеспечено применением правил графемно-фонемной конверсии. Это касается всех случаев орфографии слов, в которых не соблюдаются правила графемно-фонемного соответствия, что характерно для многих языков. Высказывается предположение, что доступ к слову путем фонемно-графемных преобразований и доступ к слову путем установления соответствия графического образа стимула и его орфографической репрезентации, который представляет собой чисто визуальный процесс, обеспечивается функционированием разных стратегий.
Для анализа подобных случаев мы обратились к другим моделям восприятия речи и распознавания слова, предусматривающим прямой доступ к орфографической репрезентации слова. Среди концепций прямого доступа наиболее известной является модель логогенов Дж. Мортона [Morton 1969; 1979]. Логоген представляет собой некоторый набор признаков и является центральным компонентом системы распознавания слова. Каждому слову или, возможно, каждой морфеме, которые известны человеку, соответствует один логоген. Распознавание слова осуществляется посредством слухового или визуального анализа стимула и сопоставления результатов этого анализа с набором признаков логогена.
С точки зрения изучения процессов и механизмов идентификации слова большой интерес представляют случаи неверного опознания значения стимула, примеры которых широко представлены в нашем экспериментальном материале. Наряду со многими другими, одной из причин неправильного опознания значения нового слова может служить факт неверного опознания графического образа прилагательного. Зарегистрировано множество примеров, когда различие в графической форме стимула и реакции заключается в одном или двух знаках: например, ВЕЗДЕСУЙНЫЙ - вездесущный, ТОЛМАЧЕСКИЙ - толкачевский, ПОРЕПАННЫЙ - потрепанный, НАЗЕРКАЛЕННЫЙ - назеркальный.
Ниже представлены некоторые ассоциативные реакции и субъективные дефиниции, свидетельствующие о неправильном опознании графической формы прилагательного НЕЗАШОРЕННЫЙ (см. рис.2). Это примеры реализации различных идентификационных моделей, но все они заставляют предположить, что на этапе доступа к слову произошла графическая “подмена” стимула. Иначе говоря, актуализация слова, близкого по графической форме стимулу, приводит к тому, что идентифицируется не само предъявленное для опознания слово, а его “графический сосед”.