Базовi алгоритми обслуговування черг
БАЗОВРЖ АЛГОРИТМИ ОБСЛУГОВУВАННЯ ЧЕРГ
1. Загальна характеристика розподiлу канальних ресурсiв
Задача розподiлу канальних ресурсiв мiж потоками розвтАЩязуiться шляхом органiзацii черг i встановленням певного порядку обслуговування поставлених у чергу пакетiв. Як було зазначено в лекцii 1, порядок обробки поставлених у чергу пакетiв визначаi частоту iхнього обслуговування, а отже, i кiлькiсть канальних ресурсiв, якi надаються даному потоку.
Черги й алгоритм iхньоi обробки i iнструментами управлiння перевантаженнями, коли мережний пристрiй не встигаi передавати пакети на вихiдний iнтерфейс в тому темпi, в якому вони надходять. Якщо причиною перевантаження i процесорний блок мережного пристрою, то для тимчасового збереження неопрацьованих пакетiв використовуiться вхiдна черга, тобто черга, зв'язана з вхiдним iнтерфейсом. У випадку, коли причина перевантаження полягаi в обмеженiй швидкостi вихiдного iнтерфейса (а вона завжди обмежена швидкiстю протоколу), то пакети тимчасово зберiгаються у вихiднiй черзi.
За своiю суттю, чергами i областi пам'ятi комутатора або маршрутизатора, де групуються пакети з однаковими прiоритетами передачi. Алгоритм обслуговування черги визначаi порядок, у якому вiдбуваiться передача пакетiв з цiii черги. Задача застосування всiх алгоритмiв зводиться до того, щоб забезпечити найкраще обслуговування трафiка з бiльш високим прiоритетом за умови, що i пакетовi з низьким прiоритетом гарантуiться вiдповiдна увага.
Алгоритм обслуговування черг як механiзм забезпечення QoS маi задовольняти таким вимогам.
1. Алгоритм обслуговування черг iз пiдтримкою QoS повинен мати засiб диференцiювання пакетiв i засiб визначення рiвня обслуговування кожного пакета.
2. Алгоритм маi гарантувати якiсть обслуговування пакетiв шляхом розподiлення ресурсiв для кожного окремого потоку трафiка або за допомогою визначення вiдносного прiоритету потокiв.
3. Алгоритм обслуговування черг iз пiдтримкою QoS маi забезпечувати захист i рiвномiрну обробку всiх потокiв трафiка з однаковим прiоритетом (наприклад, трафiка, що доставляiться без гарантiй).
4. Додатковими вимогами до алгоритму обслуговування черг i легкiсть реалiзацii i пiдтримка управлiння доступом для потокiв, що потребують гарантованого надання ресурсiв.
Механiзми обслуговування черг можна класифiкувати за такими ознаками (рис. 1): реалiзований принцип розподiлу ресурсiв (без розподiлу ресурсiв, прiоритетний розподiл шляхом застосування однойменного обслуговування, пропорцiйний розподiл шляхом кругового обслуговування черг i рiвномiрний розподiл шляхом реалiзацii максимiнноi схеми); надання гарантiй за будь-якими параметрами мережного з'iднання (у термiнах смуги пропускання або гарантованоi затримки); принцип формування черг (формування черг за потоками або за класами); режим виконання (розподiлений на процесорах VIP-плат або нерозподiлений на центральному процесорi маршрутизатора).
Найчастiше в маршрутизаторах i комутаторах застосовуються такi алгоритми обробки черг:
- алгоритм FIFO;
- прiоритетне обслуговування (Priority Queuing, PQ);
- справедливе обслуговування (Fair Queuing, FQ);
- обслуговування на основi класу (Class Based Queuing, CBQ);
- зважене справедливе обслуговування (Weighted Fair Queuing, WFQ);
- зважене справедливе обслуговування на основi класу (Class Based WFQ, CBWFQ);
- обслуговування з малою затримкою (Low Latency Queuing, LLQ);
- зважене кругове обслуговування (Weighted Round-Robin, WRR) i його модифiкацii;
- кругове обслуговування з дефiцитом (Deficit Round-Robin, DRR) i його модифiкацii.
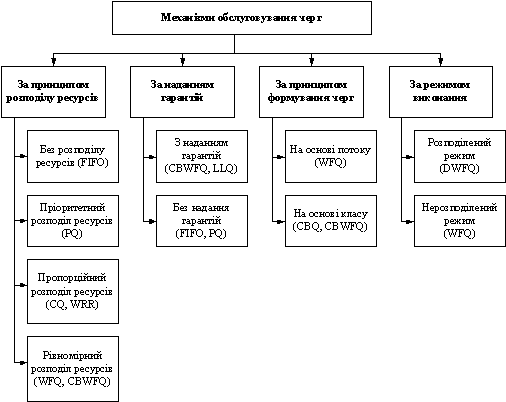
Рисунок 1 тАУ Класифiкацiя механiзмiв обслуговування черг
2. Механiзм обслуговування черг FIFO
обслуговування алгоритм черга комутатор
FIFO (First In тАУ First Out, "першим прийшов тАУ першим пiшов") i найпростiшим механiзмом обслуговування черг, вiдповiдно до якого пакети передаються на вихiд у тому порядку, в якому вони надiйшли на вхiд.
Цей механiзм i алгоритмом обробки черг за замовчуванням у всiх пристроях з комутацiiю пакетiв. Незаперечною його перевагою i простота реалiзацii i вiдсутнiсть потреби в конфiгуруваннi. Головний недолiк тАУ неможливiсть диференцiйованоi обробки пакетiв рiзних потокiв. Усi пакети знаходяться у загальнiй черзi на рiвних правах тАУ i пакети чутливого до затримок мовного трафiка, i пакети нечутливого до затримок, але дуже iнтенсивного трафiка резервного копiювання, тривалi пульсацii якого можуть надовго затримати мовний пакет. РЖншими словами механiзм FIFO не здатний забезпечити рiвномiрне обслуговування потокiв трафiка з однаковим прiоритетом i захистити iх вiд потокiв з нерiвномiрною iнтенсивнiстю, вiн допускаi перевагу потокiв високоi iнтенсивностi над всiма iншими потоками трафiка. Отже, черги FIFO необхiднi для нормальноi роботи мережних пристроiв, але iх недостатньо для пiдтримки диференцiйованоi якостi обслуговування. Черги FIFO за замовчуванням застосовуються для iнтерфейса зi швидкiстю вище 2 Мбiт/с (наприклад, Ethernet).
3. Механiзм прiоритетного обслуговування черг PQ
Механiзм прiоритетного обслуговування черг припускаi наявнiсть чотирьох вихiдних пiдчерг тАУ пiдчерги з високим, середнiм, звичайним i низьким прiоритетом обслуговування. Належнiсть потоку трафiка до кожноi з чотирьох черг визначаiться мережним адмiнiстратором. Пакети, що знаходяться у черзi з високим прiоритетом обслуговування, передаються першими. Коли ця черга виявляiться порожньою, починаiться передача пакетiв наступноi за прiоритетом обслуговування черги i т.д. Вiдзначимо, що передача пакетiв черги iз середнiм прiоритетом обслуговування не почнеться доти, доки не будуть обслугованi всi пакети черги з вищим прiоритетом. Механiзм прiоритетного обслуговування черг PQ пiдтримуi класифiкацiю пакетiв у залежностi вiд вхiдного iнтерфейса, простого або розширеного списку доступу на пiдставi IP-адреси, розмiру пакета i аплiкацii, що згенерувала цей пакет. Слiд зазначити, що некласифiкований трафiк за замовчуванням належить до черги зi звичайним прiоритетом обслуговування. У межах черги пакети обробляються вiдповiдно до механiзму FIFO. Обмежений розмiр буферноi пам'ятi мережного пристрою вимагаi, щоб черги пакетiв, що очiкують обслуговування, мали деяку граничну довжину. Звичайно за замовчуванням усiм прiоритетним чергам надаються однаковi буфери, але багато пристроiв дозволяють адмiнiстраторовi призначати кожнiй черзi буфер iндивiдуального розмiру. Прiоритетне обслуговування черг забезпечуi високу якiсть обслуговування для пакетiв iз черги з найвищим прiоритетом. Якщо середня iнтенсивнiсть iхнього надходження в пристрiй не перевершуi пропускноi здатностi вихiдного iнтерфейса (i продуктивностi внутрiшнiх блокiв самого пристрою), то пакети вищого прiоритету завжди отримують ту пропускну здатнiсть, що iм потрiбна. Рiвень затримок пакетiв з найвищим прiоритетом також мiнiмальний. Що ж стосуiться iнших класiв прiоритетiв, то якiсть iхнього обслуговування буде нижчою, нiж у пакетiв найвищого прiоритету, причому рiвень зниження заздалегiдь передбачити досить важко. Це залежить вiд iнтенсивностi трафiка з найвищим прiоритетом. Прiоритетне обслуговування пакетiв потрiбно в мережах, де передача трафiка, необхiдного для розвтАЩязання критично важливих задач, маi бути здiйснена навiть за умови повного домiнування трафiка з найвищим прiоритетом в моменти перевантаження мережi. Тому прiоритетне обслуговування зазвичай застосовуiться в тому випадку, коли в мережi i один клас трафiка, наприклад, мовний трафiк, чуттiвий до затримок, але його iнтенсивнiсть невелика, так що його обслуговування не занадто знижуi якiсть передачi пакетiв iншого трафiка. Отже, головною перевагою прiоритетного обслуговування i вiдносна простота в реалiзацii i висока якiсть обслуговування трафiка з найвищим прiоритетом. Основнi недолiки полягають у такому:
- необхiднiсть ретельного контролю трафiка на етапi доступу в мережу з метою належного надання прiоритету;
- вiдсутнiсть верхньоi межi для кожного з рiвнiв прiоритету;
- високий ризик подавлення низькопрiоритних потокiв потоками з найвищим прiоритетом.
4. Зваженi черги, що настроюються
Механiзм CQ (Custom Queuing, CQ, "черга, що настроюiться" або "звичайна черга") надаi адмiнiстратору можливiсть вручну задати розподiл ресурсiв, тобто розподiлити смугу пропускання. РЖнодi CQ називають також механiзмом замовленого резервування ресурсiв. Механiзм CQ обробляi кожну непорожню чергу в режимi кругового обслуговування (Round Robin), усякий раз передаючи з цiii черги певну кiлькiсть пакетiв, яка додатково настроюiться. Замовлене обслуговування черг дозволяi гарантувати надання певноi частини смуги пропускання трафiка, необхiдному для виконання критично важливих задач, у той же час не забуваючи i про iнший трафiк мережi. Механiзм замовленого обслуговування черг CQ пiдтримуi класифiкацiю пакетiв у залежностi вiд вхiдного iнтерфейса, простого або розширеного списку доступу на пiдставi IP-адреси, розмiру пакета та аплiкацii, що згенерувало цей пакет. Вiдповiдно до механiзму CQ трафiк можна розподiлити за 16 чергами (рис. 2). Крiм цього, iснуi додаткова нульова системна черга, яка призначена виключно для обробки високопрiоритетних пакетiв, таких, як пакети пiдтримки з'iднання i управляючих пакетiв. Ця черга i прiоритетною i ii пакети передаються першими. Трафiк користувачiв не може оброблятися в системнiй черзi.
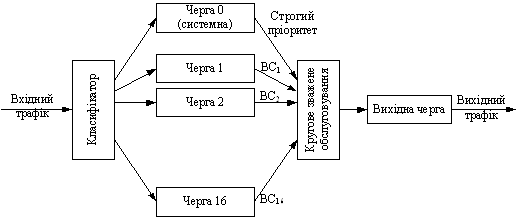
Рисунок 2 тАУ Механiзм замовленого обслуговування черг CQ
У рамках CQ черги 1тАУ16 обслуговуються за круговим принципом, починаючи з першоi. З кожною чергою пов'язаний свiй лiчильник байт (Byte Count, BC), який визначаi кiлькiсть байтiв, що маi бути передана з цiii черги, перш нiж перейти до наступноi. Пакети з черги передаються доти, поки не перевищиться значення лiчильника байт або черга не виявиться порожньою. Пiсля цього система переходить до наступноi непорожньоi черги. Вiдзначимо, що якщо значення лiчильника байт було перевищено, пакет, що передаiться в поточний момент часу, передаiться повнiстю. Наприклад, якщо значення лiчильника байтiв дорiвнюватиме 100, а розмiр пакета тАУ1024 байта, то щораз при обслуговуваннi даноi черги маршрутизатор передаватиме 1024, а не 100 байт.
Припустимо, що розмiр пакетiв трьох рiзних протоколiв дорiвнюi 500, 300 i 100 байт вiдповiдно. Для того, щоб рiвномiрно розподiлити смугу пропущення мiж трьома протоколами, ви можете спробувати встановити значення лiчильника байтiв для кожноi черги рiвним 200. Слiд зазначити, що подiбне рiшення, проте, не приведе до розподiлу смуги пропускання в пропорцii 33/33/33. Коли маршрутизатор обслуговуi першу чергу, вiн передаi щораз 500-байтовий пакет iнформацii; другу чергу тАУ 300-байтовий пакет; третю чергу тАУдва 100-байтових пакета. Отже, дiйсний розподiл смуги пропускання здiйснюiться в пропорцii 50/30/20. До такого непередбачуваного результату призвело занадто мале значення лiчильника байтiв.
Насправдi досить велике значення лiчильникiв байтiв також може призвести до досить небажаного розподiлу смуги пропускання. Якщо всiм трьом чергам надати значення лiчильника байтiв, яке дорiвнюi 10 Кбайт, то, незважаючи на те, що пакети кожного з протоколiв обслуговуватимуться швидко в момент обробки черги, вiдповiдноi цьому протоколовi, може пройти досить багато часу, перш нiж ця черга обслуговуватимуться знову. У розглянутому нами випадку одним з найбiльш оптимальних рiшень i установка значень лiчильникiв байтiв черг таким, що дорiвнюють 500, 600 i 500 байт вiдповiдно, що приведе до розподiлу смуги пропускання в пропорцii 31:38:31.
Отже, задача розподiлу смуги пропускання в заданих пропорцiях мiж декiлькома потоками зводиться до визначення коректного значення лiчильника байтiв. Для розрахунку такого значення лiчильника байтiв BC пропонуiться такий алгоритм.
Нехай потрiбно розподiлити смугу пропускання мiж трьома чергами в пропорцii ![]() Ваз огляду на те, що розмiри пакетiв, що надходять у кожну з цих черг, складають
Ваз огляду на те, що розмiри пакетiв, що надходять у кожну з цих черг, складають ![]() ,
, ![]() ,
, ![]() Вавiдповiдно.
Вавiдповiдно.
Крок 1. Розраховуються допомiжнi змiннi 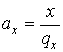 ,
, 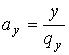 ,
, 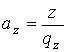 .
.
Крок 2. Отриманi значення ![]() ,
, ![]() ,
, ![]() Ванормалiзуються й округляються у бiльший бiк до найближчого цiлого числа
Ванормалiзуються й округляються у бiльший бiк до найближчого цiлого числа
 ,
,
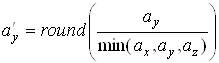 ,
,  .
.
Крок 3. Розраховуються значення лiчильникiв байтiв
![]() ,
, ![]() ,
, ![]() .
.
Крок 4. Розраховуiться розподiл смуги мiж чергами, який забезпечуiться отриманими значеннями лiчильникiв байтiв ![]() ,
, ![]() ,
, ![]() :
:
 ,
,
де ![]() ВатАУ загальна кiлькiсть черг. У даному прикладi
ВатАУ загальна кiлькiсть черг. У даному прикладi ![]() =3.
=3.
Крок Якщо отриманий розподiл значно вiдхиляiться вiд заданого (![]() ), то необхiдно повернутися до кроку 2 i помножити коефiцiiнти пропорцii кiлькостi пакетiв з кожноi черги, що мають передаватися за один раз,
), то необхiдно повернутися до кроку 2 i помножити коефiцiiнти пропорцii кiлькостi пакетiв з кожноi черги, що мають передаватися за один раз, 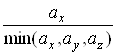 ,
, 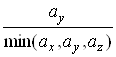 ,
,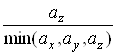 Ва(до операцii округлення) на деяке спецiальне число. Це число пiдбираiться, виходячи з мiркувань максимального наближення коефiцiiнтiв пропорцiй до цiлих чисел, хоча воно не обов'язково маi бути цiлим.
Ва(до операцii округлення) на деяке спецiальне число. Це число пiдбираiться, виходячи з мiркувань максимального наближення коефiцiiнтiв пропорцiй до цiлих чисел, хоча воно не обов'язково маi бути цiлим.
5. Алгоритм органiзацii черг на основi класу CBQ
Алгоритм CBQ (Class-Based Queuing) забезпечуi iiрархiчний розподiл ресурсiв i цiкавий у першу чергу iiрархiчним пiдходом в органiзацii черг.
У рамках CBQ смуга пропускання каналу подiляiться мiж декiлькома класами трафiка в заздалегiдь заданих спiввiдношеннях, причому кожному з класiв у перiод перевантаження гарантуiться певна частка загальноi смуги. За вiдсутностi перевантаження смугу пропускання, яку видiлено для одного класу трафiка i яка не використовуiться ним цiлком, можна роздiлити мiж iншими класами, iнтенсивнiсть надходження яких перевищуi видiлену iм смугу. У рамках CBQ використовуiться два планувальника: загальний планувальник (general scheduler) i планувальник розподiлу ресурсiв (link-sharing scheduler), мiж якими проводиться строге розмежування (рис. 3).
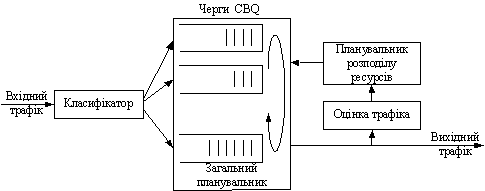
Рисунок 3 тАУ Механiзм CBQ
Вхiдний трафiк класифiкуiться i роздiляiться на кiлька черг вiдповiдно до заздалегiдь заданих правил фiльтрацii. Загальний планувальник (як правило, це WRR) визначаi, з якоi черги обслуговуватиметься наступний пакет. Черга вибираiться виходячи з того, щоб гарантувати кожному класу трафiка щонайменше задану частку вiд сумарноi пропускноi здатностi каналу (гарантована смуга). У рамках окремих черг використовуiться механiзм FIFO.
Вихiдний трафiк контролюiться шляхом оцiнки часу мiж сусiднiми пакетами одного класу трафiка. На пiдставi цiii iнформацii трафiк класифiкуiться як такий, що перевищуi лiмiт (over-limit), як такий, що укладаiться в лiмiт (under-limit) або як такий, що залишився (at-limit). Трафiк вважаiться як таким, що перевищуi лiмiт, якщо смуга, яку вiн використовуi бiльше, нiж йому гарантуiться, вiдповiдно трафiк i таким, що укладаiться в лiмiт, якщо вiн використовуi смугу менше йому гарантованоi.
Якщо черга якого-небудь класу трафiка виявиться порожньою, планувальник розподiлу ресурсiв роздiлить гарантовану даному класовi смугу мiж iншими класами. У випадку виникнення перевантаження, планувальник розподiлу ресурсiв переводить клас, що перевищив лiмiт, у розряд пасивного i загальний планувальник тимчасово не обслуговуi пакети з цiii черги.
Як уже вiдзначалося вище, у CBQ застосовуiться iiрархiчний пiдхiд до розподiлу ресурсiв (hierarchical link-sharing). Для окремого класу трафiка в CBQ створюiться своя черга, причому iснують рiзнi варiанти побудови критерiiв класифiкацii, наприклад, класифiкацiя може базуватися на аплiкацii, яка згенерувала пакет, або на адресах вiдправника й одержувача. Приклади вiдповiдних схем подiлу ресурсiв наведенi на рис. 4. На рис. 4 для кожного класу трафiка зазначена частка сумарноi смуги пропускання, гарантована даному класовi в умовах перевантаження. Видiлення якому-небудь класовi 0% означаi, що в перiод перевантаження даному класовi не гарантуiться передача.
Приклад iiрархiчного розподiлу ресурсiв наведений на рис. 5
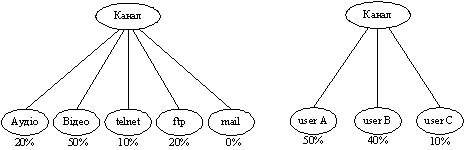
Рисунок 4 тАУ Приклади розподiлу ресурсiв з використанням рiзних критерiiв класифiкацii трафiка
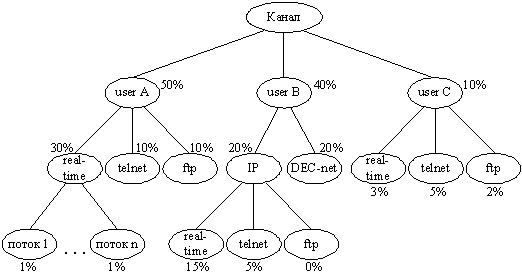
Рисунок 5 тАУ Приклад iiрархiчного розподiлу ресурсiв
Механiзм обслуговування CBQ i дуже розповсюдженим, вiн реалiзований у Packet Filter (pf) у сiмействi операцiйних систем BSD.
Розглянемо приклад. Нехай маiмо таку структуру черг:
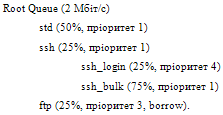
Тут Root Queue тАУ коренева черга тАУ займаi всю смугу пропускання каналу (2 Мбiт/с). Коренева черга маi три дочiрнi черги std, ssh i ftp, яким надаiться 50%, 25% i 25% вiд сумарноi смуги вiдповiдно. Черга ssh у свою чергу маi двi дочiрнi пiдчерги: ssh_login i ssh_bulk, що подiляють смугу, яку видiлено для ssh, в спiввiдношеннi 1:3 (25% i 75%).
У рамках CBQ можливе введення прiоритетiв. Черги одного рiвня iiрархii i рiвного прiоритету обслуговуються за круговим принципом (WRR). Черга, що маi вищий прiоритет, обслуговуiться першою. У даному прикладi спочатку обслуговуiться черга ftp (прiоритет 3), потiм черги з прiоритетом 1 тАУ std i ssh за круговим принципом. Коли обслуговуватиметься черга ssh, спочатку вилучаються пакети з ssh_login (прiоритет 4), потiм з ssh_bulk (прiоритет 1). Прiоритети черг рiзного рiвня iiрархii (ftp i ssh_login) не порiвнюються. Запис borrow для черги ftp означаi, що цiй черзi дозволено запозичати ресурси (смугу пропускання), якi видiленi для iнших черг цього ж рiвня iiрархii, але ними не використовуються. Розглянута черга конфiгуруiться на iнтерфейсi fxp0 за допомогою наступних команд:

Тут записи ecn i red означають, що в цих чергах працюють механiзми боротьби з перевантаженнями ECN i RED.
6. Максимiнна схема рiвномiрного розподiлу ресурсiв
З метою забезпечення рiвномiрного обслуговування використовуiться максимiнна схема рiвномiрного розподiлу ресурсiв (max-min fair-share allocation scheme). Основними ii правилами i такi:
тАв ресурси розподiляються в порядку пiдвищення вимог;
тАв користувач не може отримати обсяг ресурсiв, який перевищуi його потреби;
тАв ресурси розподiляються рiвномiрно мiж користувачами з незадоволеними вимогами.
Розглянемо приклад. Припустимо, що загальний обсяг доступного ресурсу дорiвнюi 14 одиницям. Вимоги до ресурсу користувачiв А, В, С, D та Е складають 2, 2, 3, 5 i 6 одиниць, вiдповiдно. Розподiл ресурсу починаiться з джерела з найменшими вимогами, який одержуi обсяг ресурсу, що дорiвнюi вiдношенню всього запасу ресурсу до загальноi кiлькостi користувачiв. Отже, у розглянутому нами випадку користувачам А i В буде надано 14/5=2,8 одиниць ресурсу (рис. 6). Однак вимоги користувачiв А i В складають усього лише 2 одиницi ресурсу. У цьому випадку надлишковий ресурс обсягом 1,6 одиниць (по 0,8 одиниць з кожного користувача) рiвномiрно розподiляiться мiж трьома iншими користувачами. Отже, користувачi С, D та Е одержують по 2,8 + (1,6/3) = 3,33 одиниць ресурсу (рис. 7). Наступним за обсягом висунутих вимог до ресурсiв i користувач С. Вимоги користувача С на 0,33 одиницi менше обсягу ресурсiв, що йому пропонуiться. Надлишковий ресурс обсягом 0,33 одиницi рiвномiрно розподiляiться мiж користувачами D i Е, кожний з яких одержуi по 3,33 + (0,33/2)=3,5 одиницi ресурсу (рис. 8).
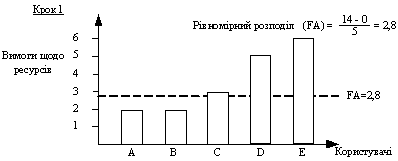
Рисунок 6 тАУ Розподiл ресурсiв для користувачiв А i В
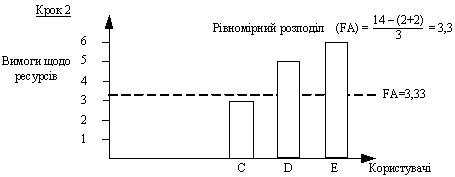
Рисунок 7 тАУ Розподiл ресурсiв для користувача С
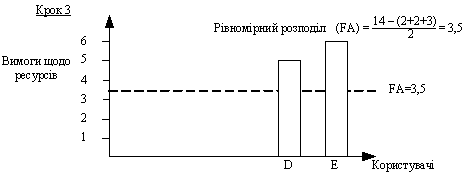
Рисунок 8 тАУ Розподiл ресурсiв для користувачiв D та E
У загальному випадку обсяг ресурсiв, наданий ![]() -му користувачевi, розраховуiться за формулою:
-му користувачевi, розраховуiться за формулою:
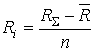 ,
,
де ![]() ВатАУ сумарний запас ресурсiв;
ВатАУ сумарний запас ресурсiв; ![]() ВатАУ обсяг уже розподiлених ресурсiв;
ВатАУ обсяг уже розподiлених ресурсiв;
![]() ВатАУ кiлькiсть користувачiв, яким ще потрiбнi ресурси.
ВатАУ кiлькiсть користувачiв, яким ще потрiбнi ресурси.
Як видно з рис. 6 тАУ 8, вимоги користувачiв А та В задовольняються в повному обсязi, тому що вони не перевищують значення, отриманого в результатi рiвномiрного розподiлу ресурсiв мiж усiма користувачами. На кроцi 2 цiлком задовольняються вимоги користувача С. А запити користувачiв D i Е залишаються незадоволеними.
Звернiть увагу, що всi користувачi з незадоволеними вимогами (тобто з вимогами, обсяг яких перевищуi iх максимiнну рiвномiрну частку), одержують рiвнi обсяги ресурсiв. Максимiнна схема рiвномiрного розподiлу ресурсiв одержала свою назву в зв'язку з тим, що користувач з незадоволеними вимогами одержуi максимум з можливих мiнiмальних рiвномiрних часток. Максимiнна схема рiвномiрного розподiлу ресурсiв, у якiй кожному користувачевi призначаiться певна вага, одержала назву зваженоi максимiнноi схеми рiвномiрного розподiлу ресурсiв (weighted max-min fair-share allocation scheme). У вiдповiдностi до зваженоi максимiнноi схеми рiвномiрного розподiлу ресурсiв кожному користувачевi надаiться рiвномiрна частка ресурсiв, пропорцiйна до його ваги. Принцип максимiнного рiвномiрного розподiлу ресурсiв було покладено в основу узагальненоi схеми подiлу процесорного часу (Generalized Processor Sharing, GPS). У вiдповiдностi зi схемою GPS кожен потiк трафiка вмiщуiться у власну логiчну чергу, пiсля чого нескiнченно малий обсяг даних з кожноi непорожньоi черги обслуговуiться за круговим принципом. Необхiднiсть обробки нескiнченно малого обсягу даних на кожному колi обумовлена вимогою рiвномiрного обслуговування всiх непорожнiх черг на будь-якому кiнцевому часовому iнтервалi. Отже, схема GPS i справедливою в будь-який момент часу. Якщо ж усiм потокам трафiка призначити вагу, то обсяг даних потоку, який оброблюiться за одне коло, буде пропорцiйний його вазi. Подiбне розширення схеми GPS фактично i зваженою максимiнною схемою рiвномiрного обслуговування. Незважаючи на те, що GPS i iдеальним втiленням максимiнноi схеми рiвномiрного розподiлу ресурсiв, цю модель не можна реалiзувати на практицi. Це пов'язано з припущенням про нескiнченно малий обсяг даних, що обслуговуються, кожного кола.
7. Алгоритм рiвномiрного обслуговування черг (FQ)
Спробою практичноi реалiзацii схеми GPS i алгоритм рiвномiрного обслуговування черг (FQ) на основi обчислення порядкового номера пакета, що iмiтуi роботу GPS-сервера, який обслуговуi в окремий момент часу 1 байт даних. Алгоритм FQ моделюi схему GPS шляхом обчислення порядкового номера кожного отриманого пакета. Власне кажучи, порядковий номер пакета i службовою позначкою, яка визначаi вiдносний порядок обробки пакетiв.
Одним з основних понять алгоритму FQ i поняття лiчильника циклiв (Round Number, RN), значення якого вiдповiдаi кiлькостi виконаних циклiв побайтового планувальника кругового обслуговування в заданий момент часу. Лiчильник циклiв безпосередньо визначаi значення порядкового номера пакета.
З метою iлюстрацii способу моделювання схеми GPS за допомогою алгоритму FQ розглянемо три потоки трафiка тАУ А, В i С, розмiри пакетiв яких складають 128, 64 i 32 байт, вiдповiдно. Пакети надходять один за iншим на завантажений FQ-сервер у порядку Al, A2, A3, Bl, C1. Першим на FQ-сервер надходить пакет А1, потiм тАУпакет А2 i т.д.
Потiк вважаiться активним (active), якщо хоча б один iз пакетiв з цього потоку знаходиться в очiкуваннi обслуговування; у iншому випадку потiк вважаiться пасивним (inactive).
Припустимо, що системою FQ був отриманий пакет А1, який належить пасивному потоковi. Повна обробка 128-байтового пакета побайтовим планувальником кругового обслуговування потребуi 128 циклiв. Якщо на момент одержання пакета А1 значення лiчильника циклiв дорiвнювало 100, то пiсля повноi передачi пакета А1 це значення складе 100+128=228. По сутi, порядковий номер пакета i номером циклу, в якому здiйснюiться передача останнього байта пакета. Оскiльки в дiйсностi планувальник за один раз реалiзуi передачу всього пакета, а не його одного байта, вiн обслуговуi весь пакет незалежно вiд того, чи зрiвнявся лiчильник циклiв з порядковим номером пакета (рис.9).
Коли система FQ отримаi пакет А2, вiн уже належатиме активному потоковi трафiка завдяки наявностi в черзi пакета А1 з порядковим номером 228. Порядковий номер пакета А2 дорiвнюватиме 228+128=356, оскiльки його слiд передати пiсля пакета А1. Аналогiчно, пакетовi A3 призначаiться порядковий номер 356+128=484. Оскiльки пакети В1 i С1 належать пасивним потокам трафiка, iхнi порядковi номери дорiвнюють 164=(100+64) i 132=(100+32), вiдповiдно (рис. 9). З урахуванням обчислених порядкових номерiв пакети будуть обслугованi в такiй послiдовностi: С1,В1, А1, А2, А3.
Отже, порядковий номер (Sequence Number) ![]() Вапакета довжиною
Вапакета довжиною ![]() Вабайт, що визначаi черговiсть його обробки, можна розрахувати за формулою:
Вабайт, що визначаi черговiсть його обробки, можна розрахувати за формулою:
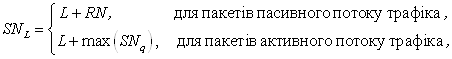 Ва(1)
Ва(1)
де ![]() ВатАУ значення лiчильника циклiв на момент надходження пакета (дорiвнюi порядковому номеровi останнього обслуговуваного пакета);
ВатАУ значення лiчильника циклiв на момент надходження пакета (дорiвнюi порядковому номеровi останнього обслуговуваного пакета); ![]() ВатАУ значення найбiльшого порядкового номера пакета, який поставлений в чергу цього потоку (для активного потоку).
ВатАУ значення найбiльшого порядкового номера пакета, який поставлений в чергу цього потоку (для активного потоку).
Лiчильник циклiв ![]() Вавикористовуiться винятково для розрахунку порядкового номера пакетiв, якi належать новим (пасивним) потокам трафiка. Порядковий номер пакетiв, що належать активним потокам трафiка, розраховуiться з урахуванням найбiльшого порядкового номера пакета з цього потоку, який поставлений в чергу.
Вавикористовуiться винятково для розрахунку порядкового номера пакетiв, якi належать новим (пасивним) потокам трафiка. Порядковий номер пакетiв, що належать активним потокам трафiка, розраховуiться з урахуванням найбiльшого порядкового номера пакета з цього потоку, який поставлений в чергу.
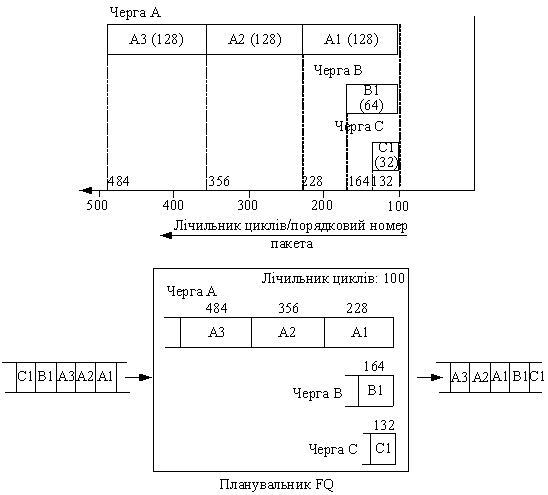
Рисунок 9 тАУ Приклад моделювання побайтового GPS-планувальника кругового обслуговування за допомогою алгоритму FQ
Слiд зазначити, що лiчильник циклiв оновлюiться при передачi кожного чергового пакета, при цьому його нове значення дорiвнюi порядковому номеровi пакета, що передаiться. Отже, якщо 32-байтовый пакет D1, що належить новому потоку, буде прийнятий у момент передачi пакета А1, значення лiчильника циклiв дорiвнюватиме 228, а порядковий номер пакета D1 тАУ 260=(228+32). Оскiльки порядковий номер пакета D1 менше порядкових номерiв пакетiв А2 i A3, вiн буде переданий ранiше за цих пакетiв. Змiна в порядку обслуговування пакетiв схематично зображена на рис. 10.
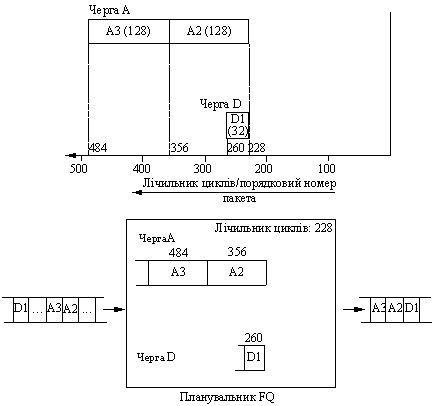
Рисунок 10 тАУ Змiна в порядку обслуговування пакетiв, яка викликана надходженням пакета D1 у момент передачi пакета А1
Вместе с этим смотрят:
IP-телефония. Особенности цифровой офисной связи
РЖсторiя звтАЩязку та його розвиток
Автоматика, телемеханика и связь